从VAE到MaskGIT(二)
本文最后更新于:March 29, 2022 pm
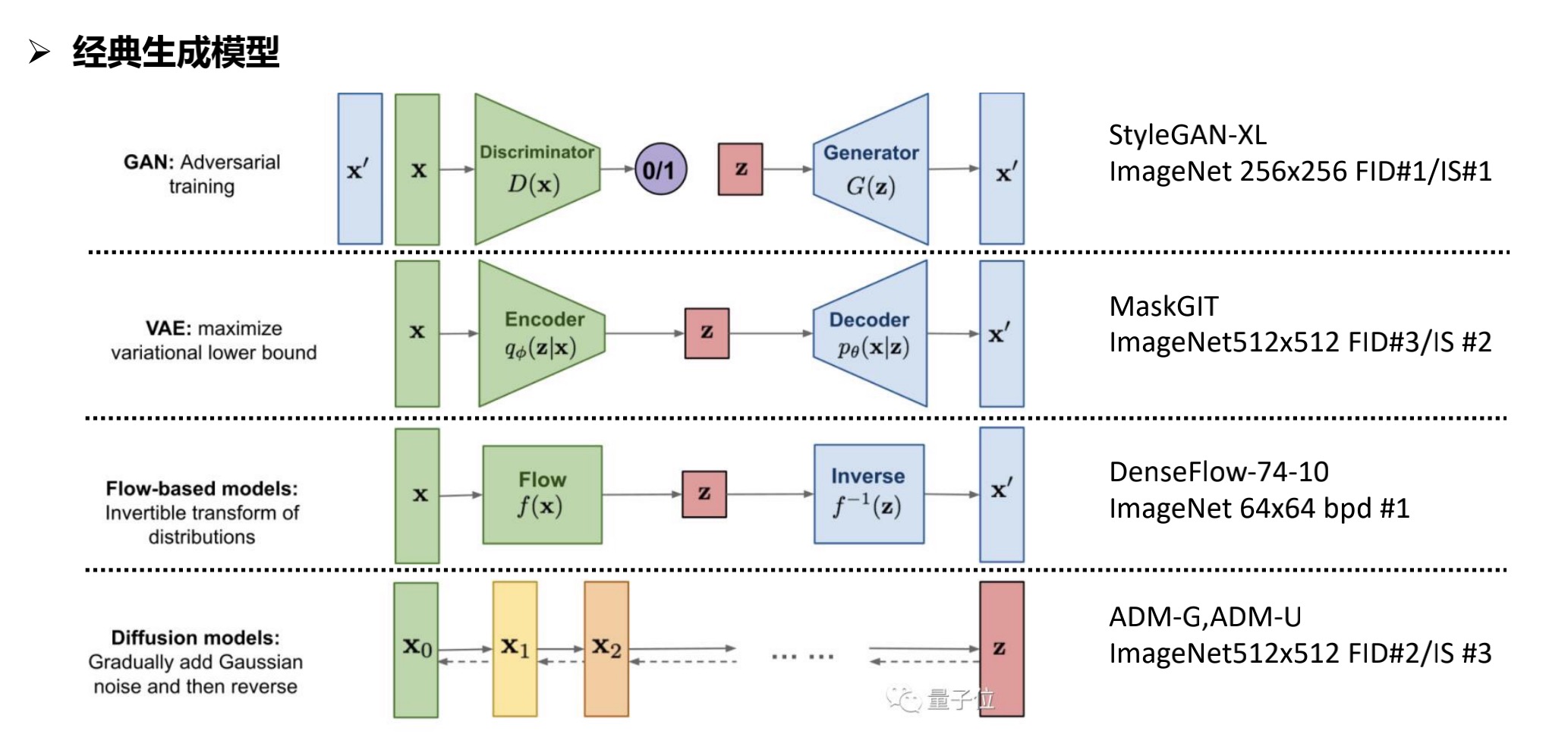
图像生成的一般要求:
- 生成的图像与真实图像相似,且清晰度比较高(具有真实性)
- 生成的图像不在原始数据集中,且尽可能地分散(具有多样性)
2. VAE-based生成式模型的改进
自编码器最早出现在1986年,而今年的一月份,TOELT LLC的AI科学家对自编码器进行了综述性的介绍[1]。自编码器包含了encoder和decoder以及一个latent code。
学习尽可能低的误差重建观测值,以更好地学习数据的特征表示
Encoder: 用于对原始的观测图像x进行压缩,以得到原始图像中基本的一些信息,称为latent code。Decoder: 对latent code进行重构,以得到重构后的图像x',- 重构误差:
然而,在自编码器的学习过程中,建立的是一对一的映射,因此latent code在隐空间里是不连续的,它的生成过程是不可控的,也就是说它对输入的噪声会十分敏感。一个常见的做法就是更改latent code的分布形式,使其尽可能地连续化。
2.1 Variational Autoencoder(VAE)
既然我们无法直接获得样本x的分布,那么我们就可以假设存在一个x对应的隐式表征z,z满足某种先验分布(人为指定),z经过解码以后可以映射到x的近似真实分布。这样做的好处是,我们可以在标准正态分布上采样得到样本近似分布,再在样本近似分布上采样来生成样本
2.1.1 变分自编码器的结构
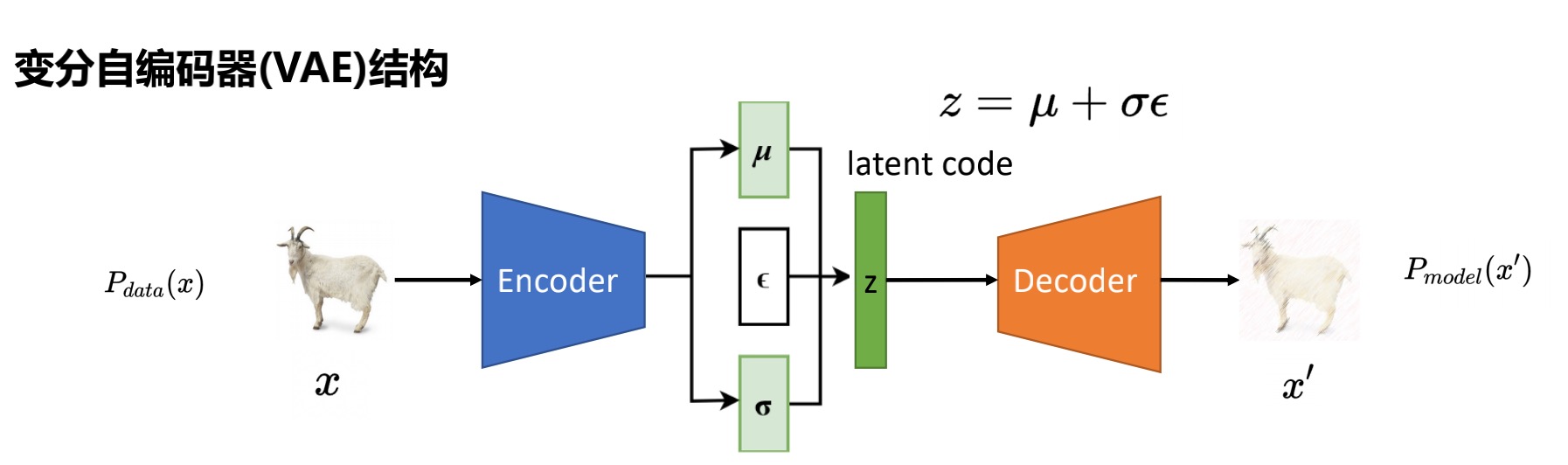
如图,变分自编码器[2]的结构与自编码器相似,不同点在于对latent code的处理。
- latent code:属性的分布既可以描述成离散的形式,也可以描述成连续的概率分布的形式,而使用连续的概率分布形式来进行属性表示可以更好地对分布进行描述,从而在生成图像过程中更好地进行采样。
Encoder: 学习 和 两个编码,同时随机采样一个正态分布的编码 来对latent code进行表示。Decoder: 根据latent code得到生成图像x'。
训练过程
通过设计latent code的分布形式,进而控制图片生成的过程。
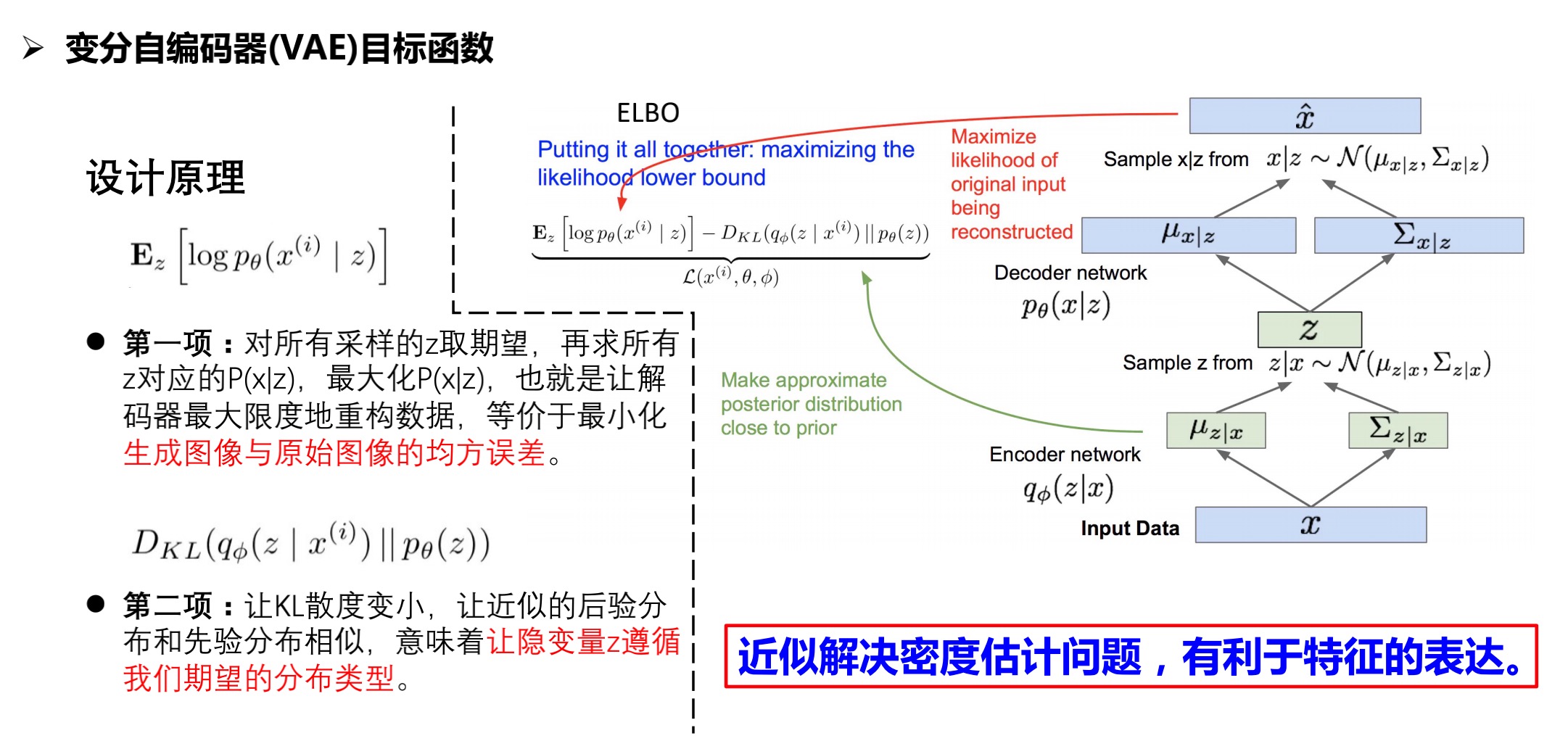
可以看出,编码器和解码器分别对应给出了z和x的条件概率分布。当训练好变分自编码器之后,生成数据只需要解码器网络,即,先从设定好的z的先验分布中采样,接着对数据x进行采样。
2.1.2 变分自编码器的后验坍塌问题(posterior collapse)
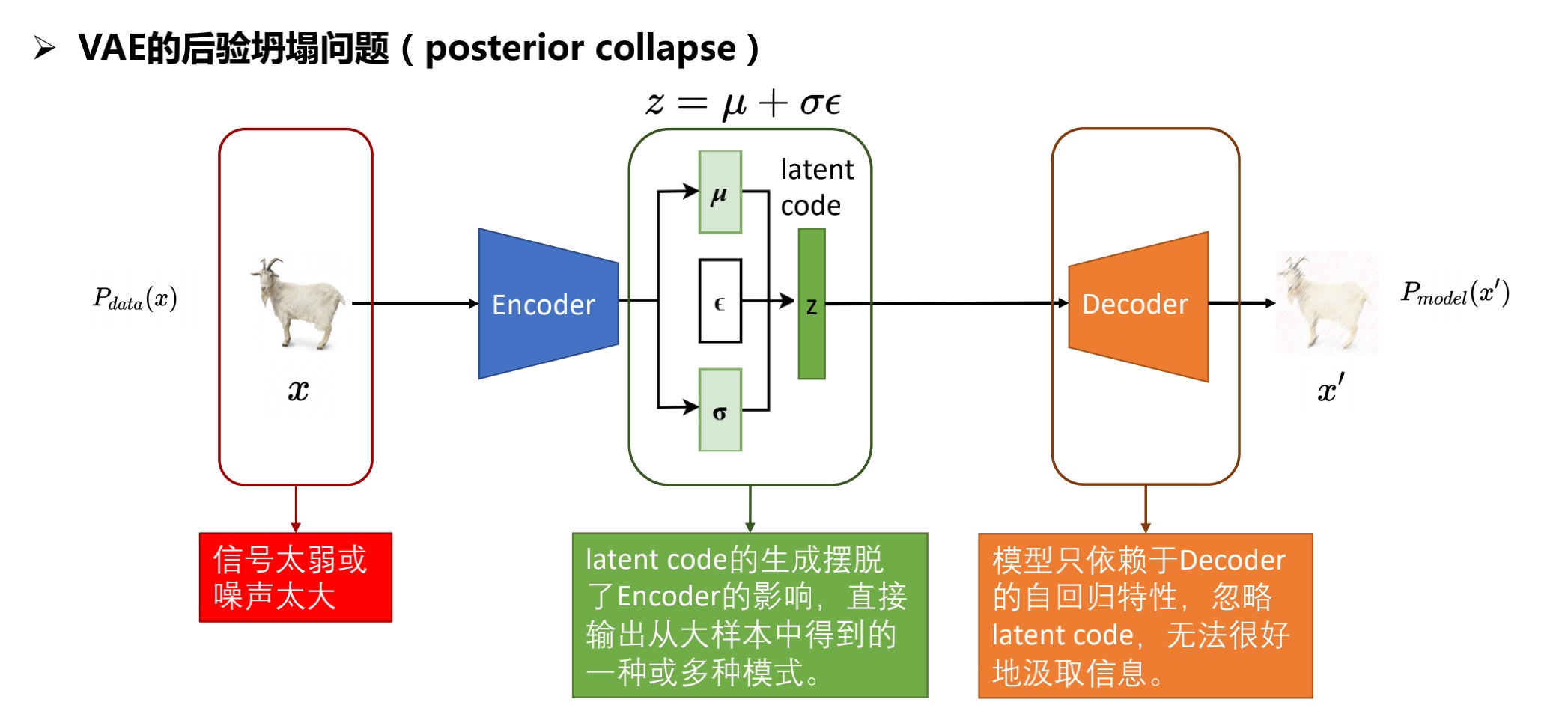
- 噪声太大:均值和方差的学习不稳定,
Decoder开始忽略z,直接自行重构。 - 信号太弱:均值和方差的学习与输入x几乎没什么关系,从而崩溃于常数值a与b,此时的z没有什么价值。
注:NeurlPS 2019 的一篇文章[3]对此现象进行了分析,表明一味的假设单一隐变量z,企图用z求边际分布来拟合真实分布,这可能是导致后验失效的真正原因。因此需要增加z分布的复杂度,而不是用单一的高斯分布。
2.2 Vector Quantised Variational Autoencoder(VQ-VAE)
摘要[4]
Learning useful representations without supervision remains a key challenge in machine learning. In this paper, we propose a simple yet powerful generative model that learns such discrete representations. Our model, the Vector Quantised-Variational AutoEncoder (VQ-VAE), differs from VAEs in two key ways: the encoder network outputs discrete, rather than continuous, codes; and the prior is learnt rather than static. In order to learn a discrete latent representation, we incorporate ideas from vector quantisation (VQ). Using the VQ method allows the model to circumvent issues of “posterior collapse” -— where the latents are ignored when they are paired with a powerful autoregressive decoder -— typically observed in the VAE framework. Pairing these representations with an autoregressive prior, the model can generate high quality images, videos, and speech as well as doing high quality speaker conversion and unsupervised learning of phonemes, providing further evidence of the utility of the learnt representations.
2.2.1 离散化表达——向量量化
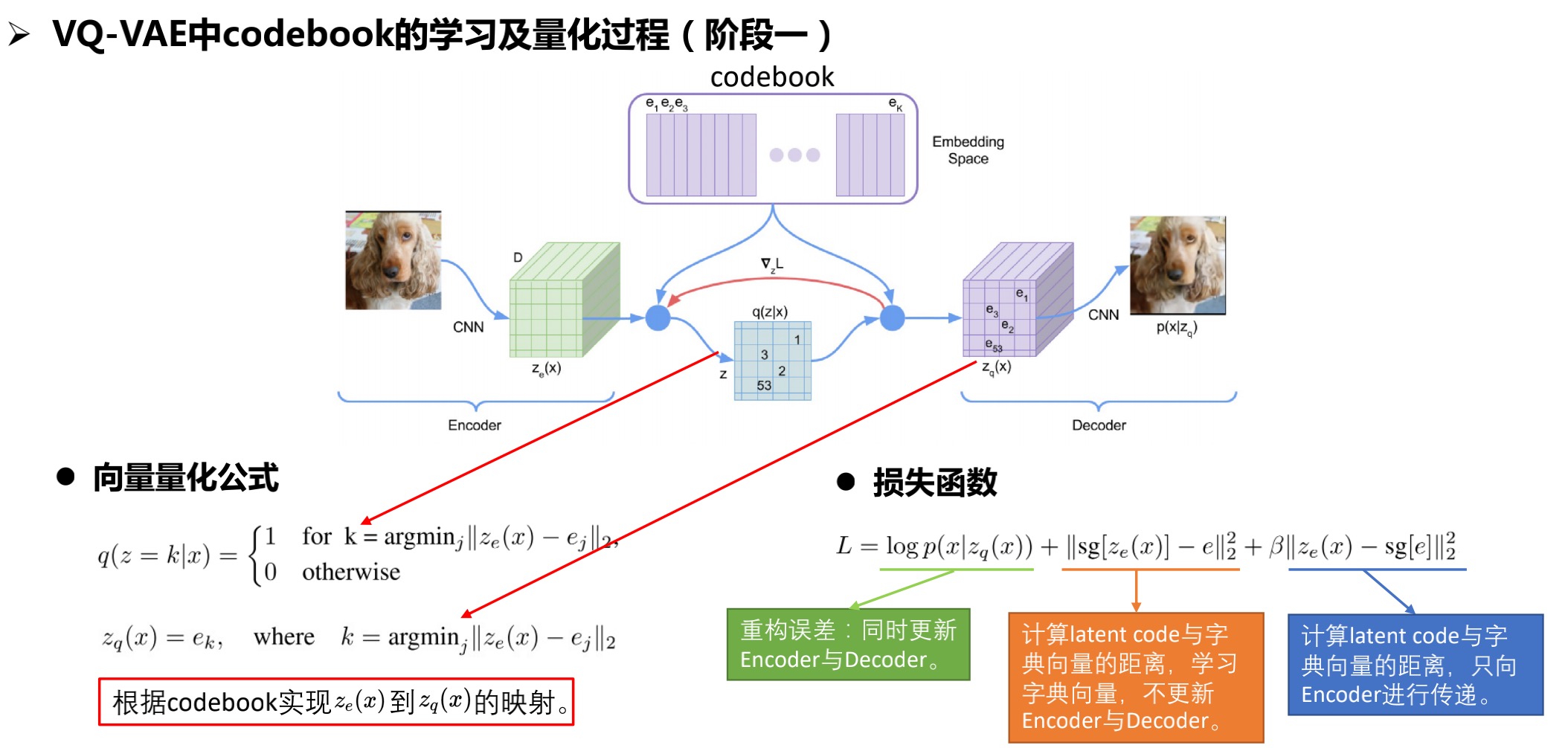
- 向量量化:找到既定点,当作某一区间的代表。既定点的依据是失真最小的少数代表向量组,也就是字典向量(codebook)。
- 方法:学习一个codebook,实现 到 的映射。
- 损失函数:第一部分是重构误差,第二部分和第三部分通过stop gradient的方式,分别对codebook和
Encoder进行学习。
2.2.2 自回归先验的引入
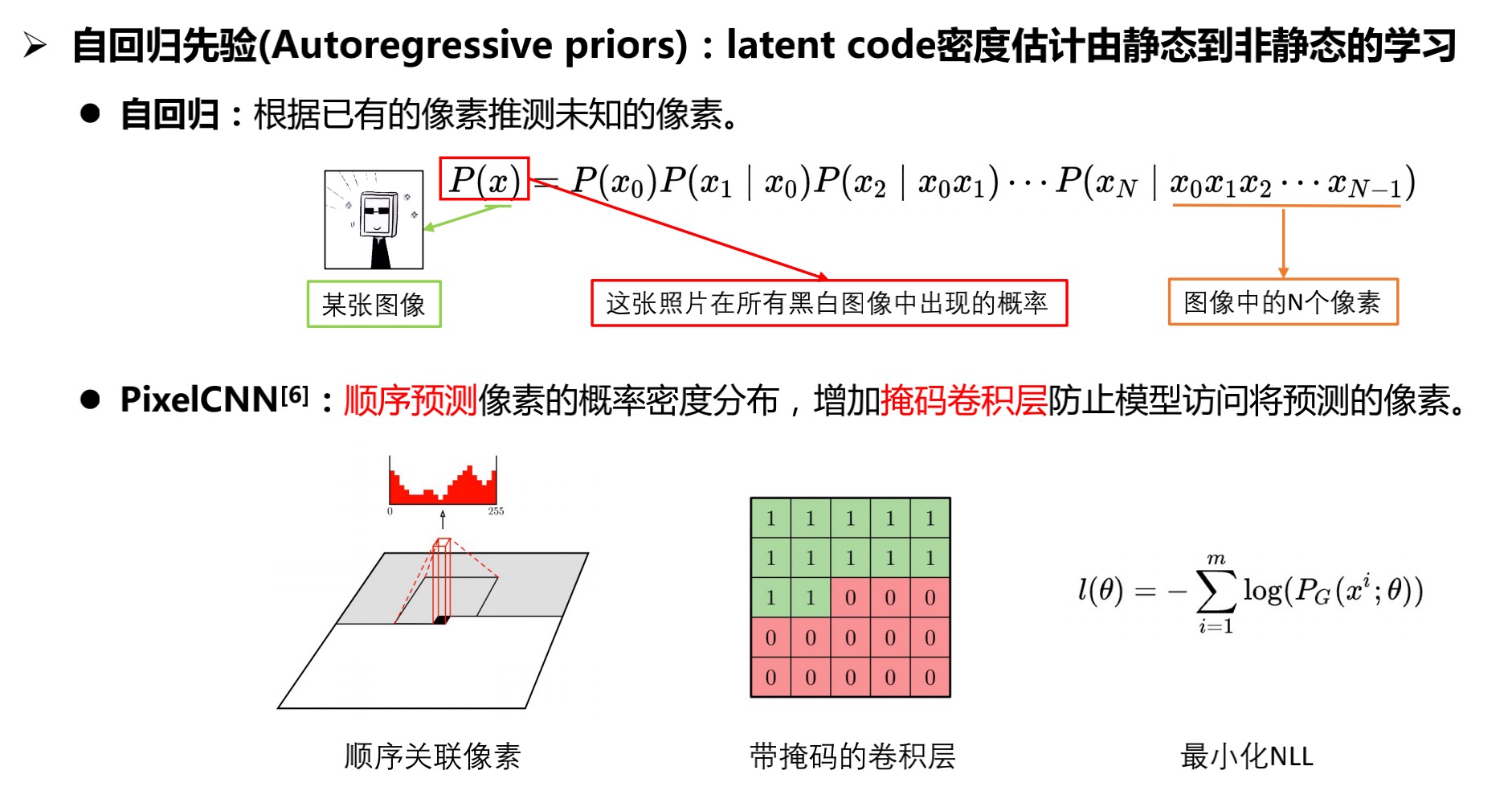
- 目的:得知整张图像在所有图像中出现的概率,就可以通过此概率进行采样,以得到生成的图像。
- 方式:通过类推连乘的方式,得到最终某一张图像出现的概率。根据条件概率依次抽取剩余像素数值,这个过程称为自回归。
- 损失函数:负对数似然。
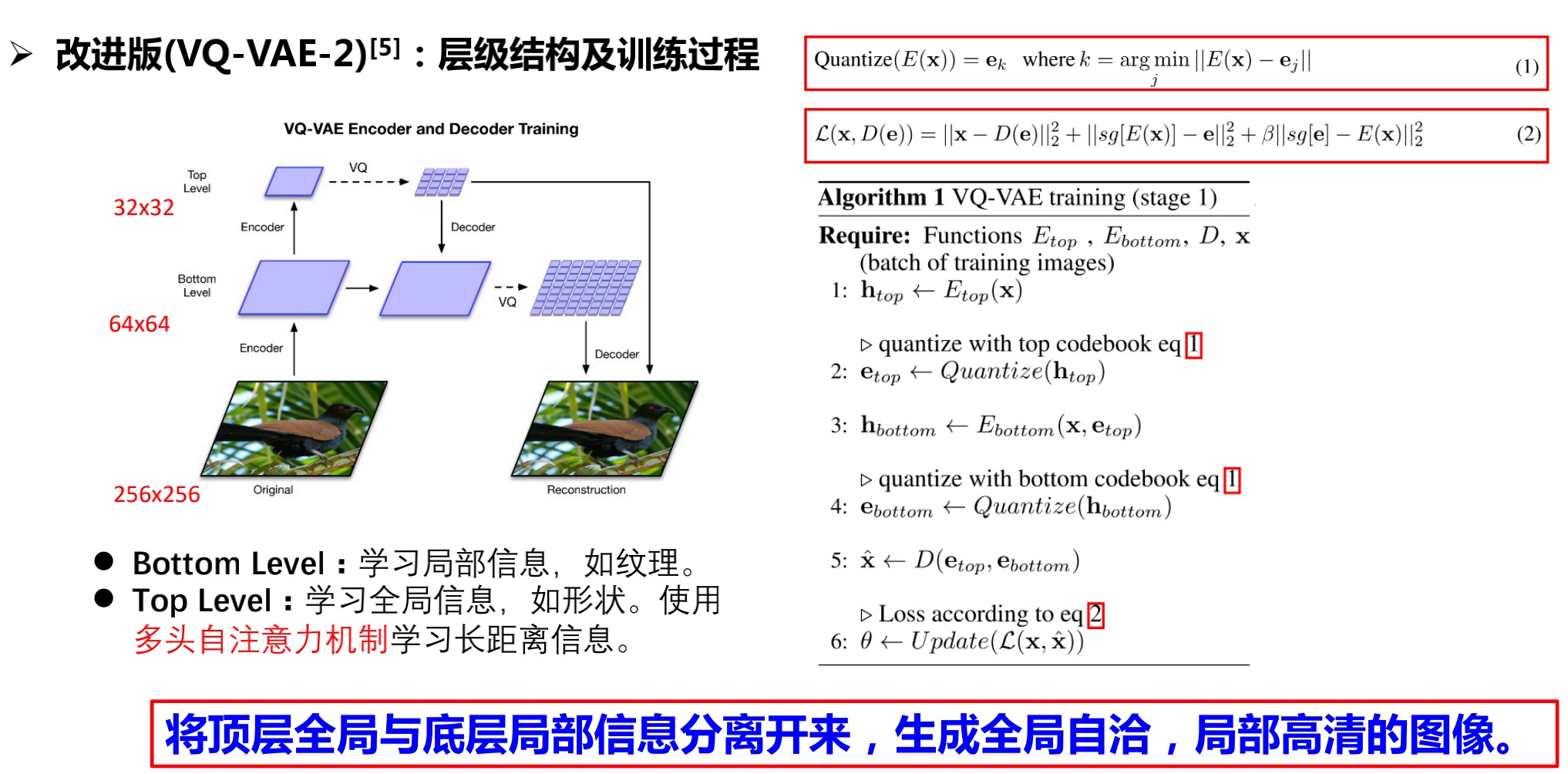
2.2.3 层级结构——VQ-VAE2

2.3 Vector Quantised Generative Adversarial Network(VQ-GAN)
摘要[5]
Designed to learn long-range interactions on sequential data, transformers continue to show state-of-the-art results on a wide variety of tasks. In contrast to CNNs, they containno inductive bias that prioritizes local interactions. This makes them expressive, but also computationally infeasible for long sequences, such as high-resolution images. We demonstrate how combining the effectiveness of the inductive bias of CNNs with the expressivity of transformers enables them to model and thereby synthesize high-resolution images. We show how to (i) use CNNs to learn a contextrich vocabulary of image constituents, and in turn (ii) utilize transformers to efficiently model their composition within high-resolution images. Our approach is readily applied to conditional synthesis tasks, where both non-spatial information, such as object classes, and spatial information, such as segmentations, can control the generated image. In particular, we present the first results on semanticallyguided synthesis of megapixel images with transformers. Project page at https://git.io/JLlvY.
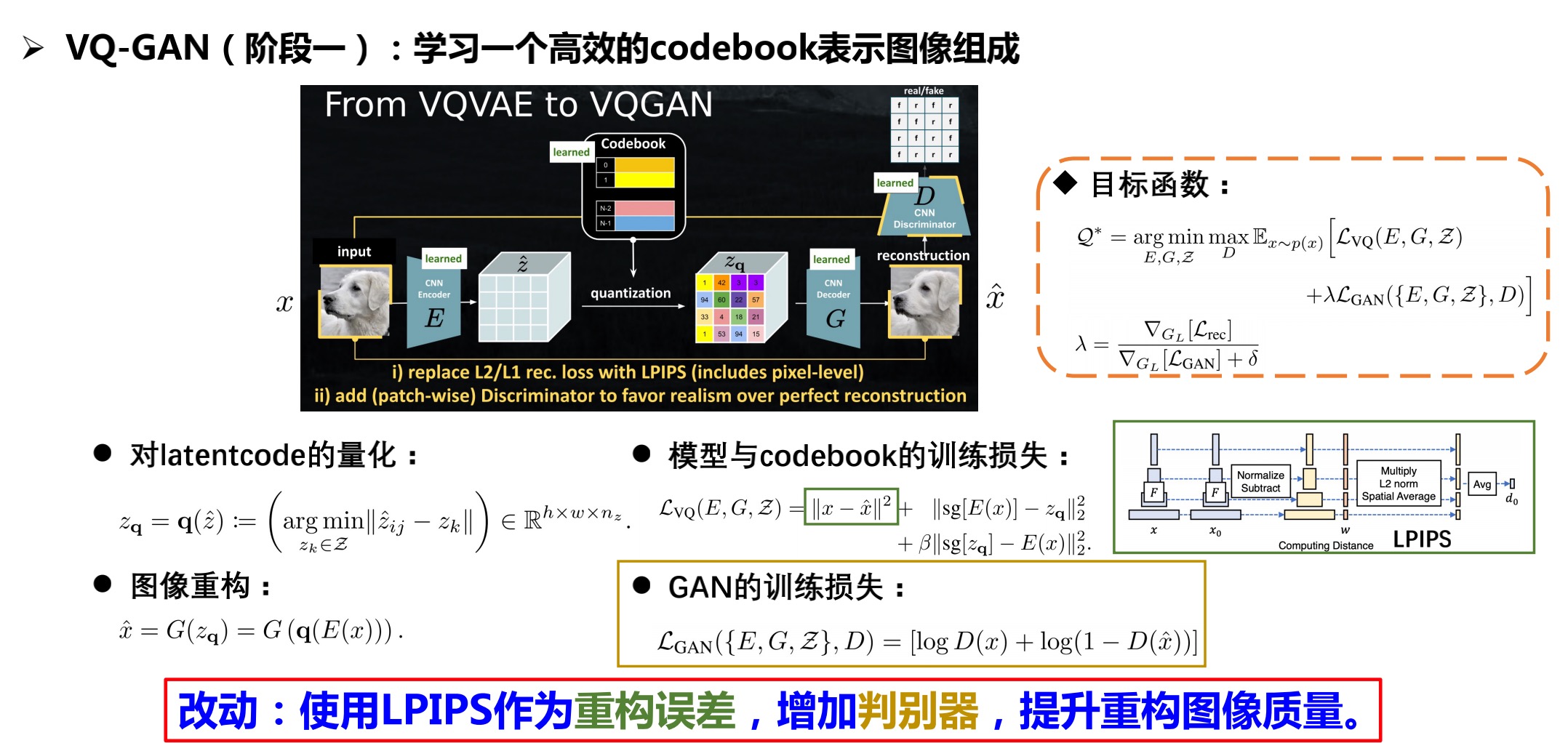
2.3.1 阶段1:损失函数的改进与GAN的引入
2.3.2 阶段2:利用Transformer学习自回归先验
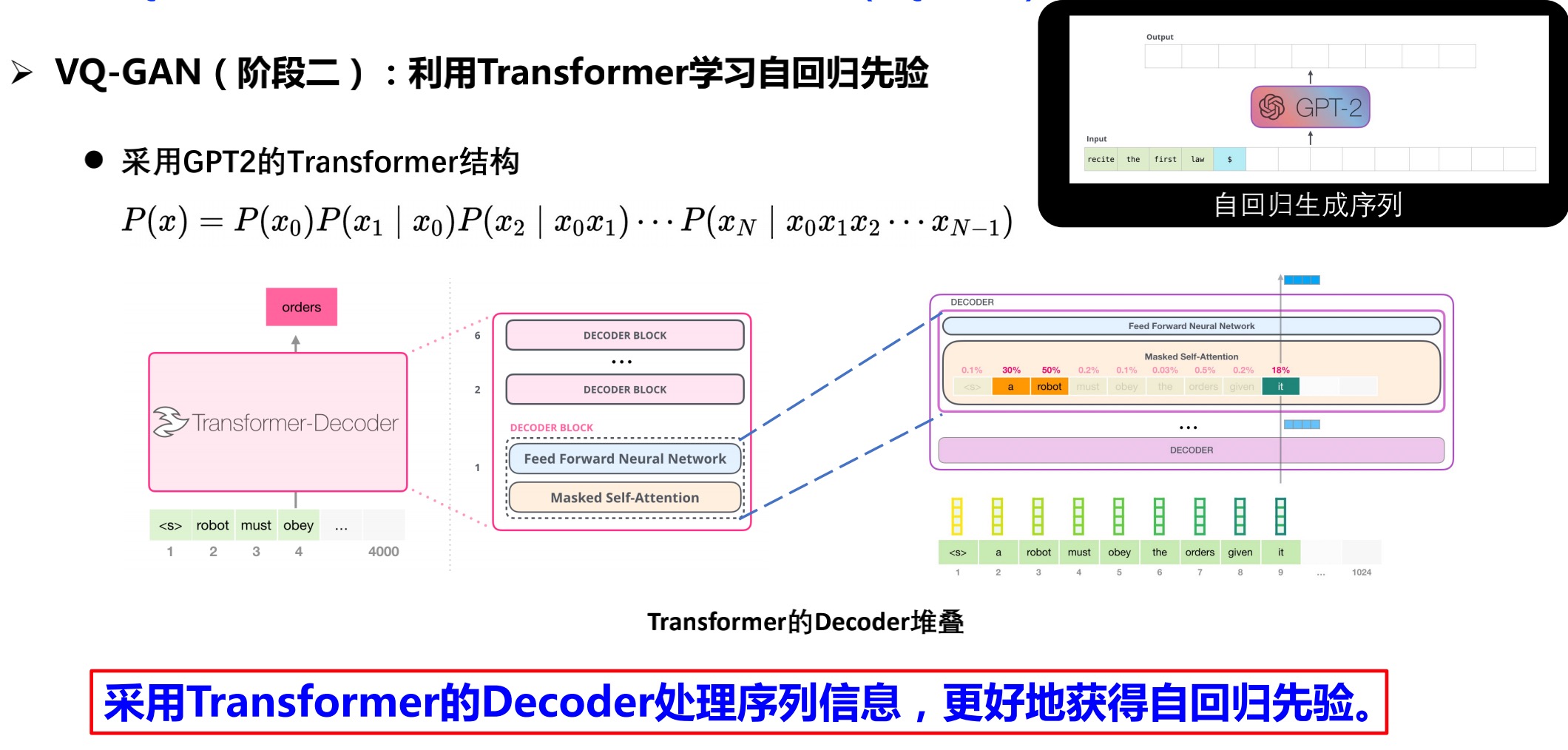
2.3.3 条件图像生成
VQ-GAN也对不同条件的图像生成进行了探索,包括有空间信息的(语义图、深度图等等)条件图像生成,以及无空间信息的条件图像生成。条件可以在自回归先验的学习过程中引入进去,而对有空间信息的条件则需要进一步的对图像进行量化,用一个具体的向量进行条件表示。

2.4 Masked Generative Image Transformer(MaskGIT)
摘要[6]
Generative transformers have experienced rapid popularity growth in the computer vision community in synthesizing high-fidelity and high-resolution images. The best generative transformer models so far, however, still treat an image naively as a sequence of tokens, and decode an image sequentially following the raster scan ordering (i.e. lineby-line). We find this strategy neither optimal nor efficient. This paper proposes a novel image synthesis paradigm using a bidirectional transformer decoder, which we term MaskGIT. During training, MaskGIT learns to predict randomly masked tokens by attending to tokens in all directions. At inference time, the model begins with generating all tokens of an image simultaneously, and then refines the image iteratively conditioned on the previous generation. Our experiments demonstrate that MaskGIT significantly outperforms the state-of-the-art transformer model on the ImageNet dataset, and accelerates autoregressive decoding by up to 64x. Besides, we illustrate that MaskGIT can be easily extended to various image editing tasks, such as inpainting, extrapolation, and image manipulation.
2.4.1 改进原因
- 直觉的角度:如画家绘画,先是框架,再逐步填充细节完善整张图像。
- 计算的角度:图像作为平面序列意味着自回归序列长度呈二次方增长。
2.4.2 MVTM的设计与训练过程
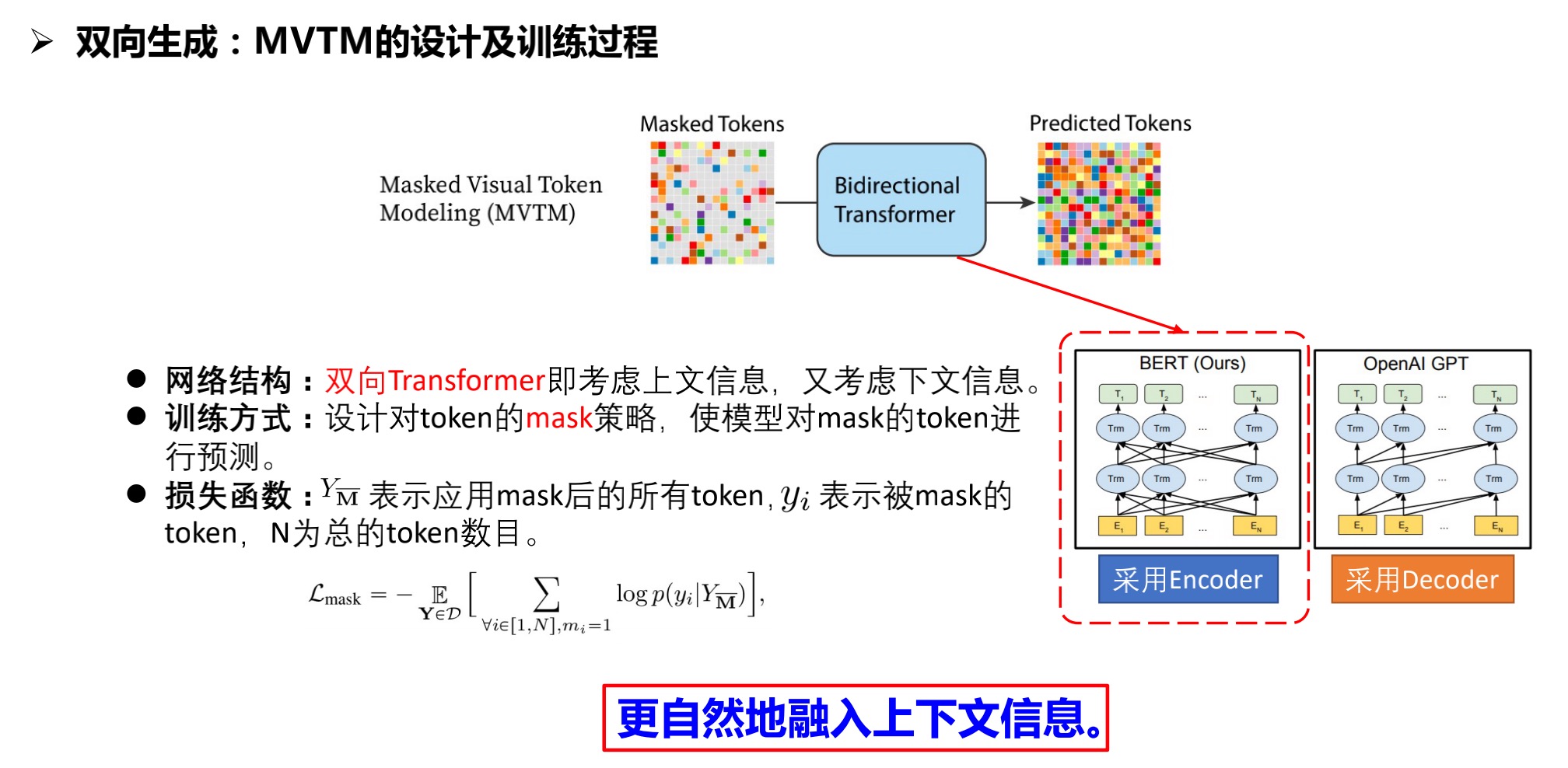
2.4.3 MVTM的图像生成步骤

2.4.4 掩码策略
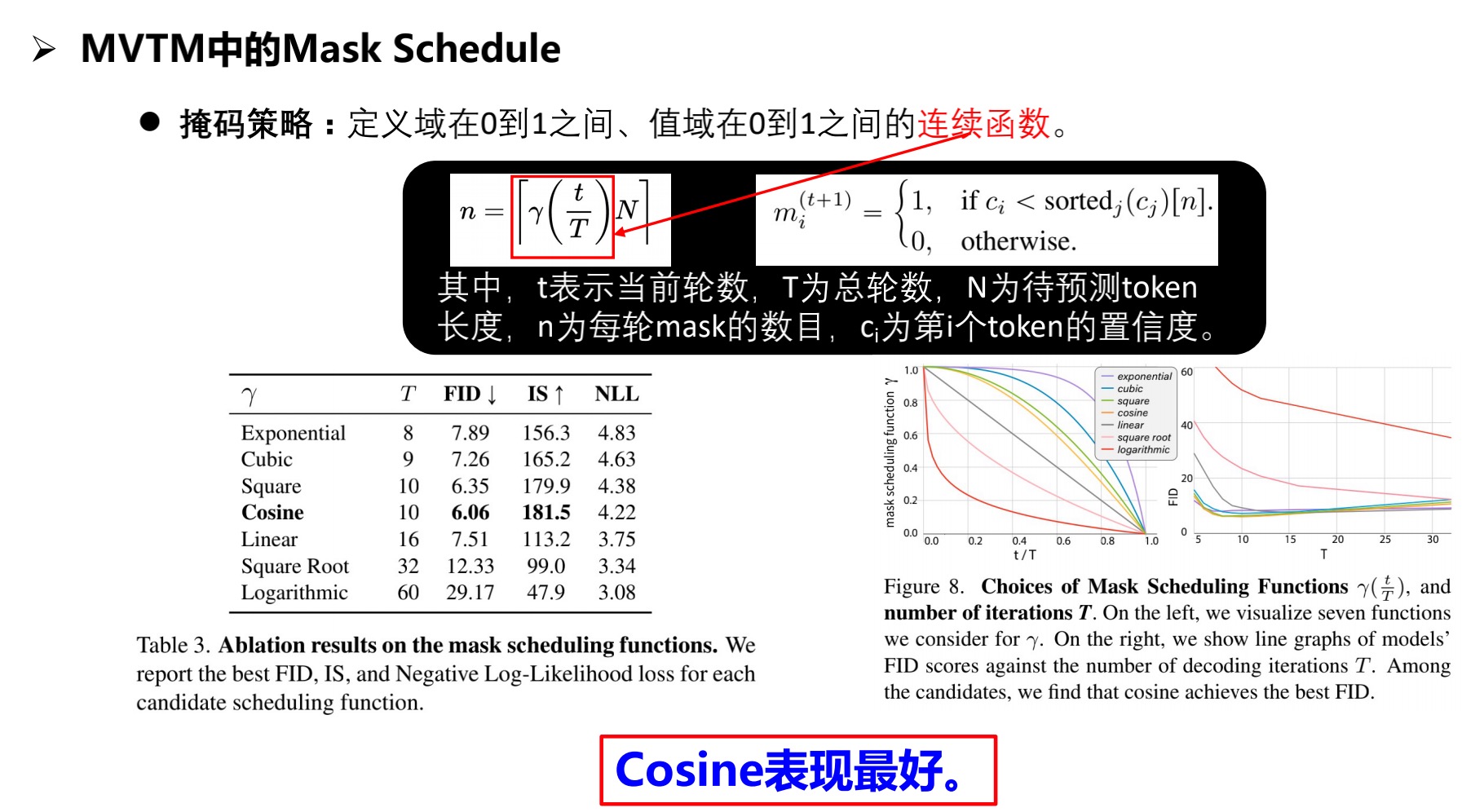
注:MaskGIT第一阶段延续了VQ-GAN的设计,第二阶段采用了Bert的双向Transformer结构,可以更快更高效地学习到图像中的上下文信息。
3. 总结与展望
3.1 总结
本质上都是解决密度估计问题,实现真实数据集与生成数据集的同分布。
图像生成的需求:
- 多样性:离散化设计latent space,学习codebook存储尽可能多的信息。
- 高清:利用Transformer更好地获取全局信息。
- 计算效率:并行解码效率优于顺序解码。
系列模型的改进:
- VAE:强制使latent code满足正态分布,以便生成新的图像。
- VQVAE:解决后验坍塌问题,使latent code有更好的表现力。
- VQVAE-2:采用多层结构,更好地获取图像结构信息与纹理信息。
- VQGAN:使用Transformer作为自回归模型,改进重构误差。
- MaskGIT:采用双向Transformer结构,并行解码,双向生成,提高计算效率。
3.2 展望
- latent code的设计:是否可以对latent code进行更好的连续化设计,以便于存储连续
的属性信息,达到更好的图像编辑的效果? - 网络结构:对Encoder而言,是否能用Transformer代替CNN,更好地利用全局信息?
- 损失函数:有无更好的重构误差,以判断生成图像与真实图像的相似性。
- Mask的设计:从绘画的角度,画者可以对图像进行修改,但MaskGIT的掩码设计是固定的不可对前一轮的mask进行修改,如果使mask可修改,应采取什么策略,是否能达到更好的效果?
3.3 其他经典生成式模型