从VAE到MaskGIT(一)
本文最后更新于:March 12, 2022 pm
摘要
本篇是关于一次组会汇报的整理,主题为《生成式模型的发展:从VAE到MaskGIT》,主要记录了三篇文章,包括了VQ-VAE、VQ-GAN以及MaskGIT。生成模型旨在模拟生成与现实世界中观察到的真实数据非常相似的数据,作为生成模型的一大分支,VAE和GAN的论文分别与2013年与2014年发表,是之后很多年图像生成任务的基石。而本次汇报讲述的是VAE(变分自编码器)的这一大分支的一些发展,包括它面临的一些问题与这些问题的解决方案。
1. 引言
1.1 什么是生成式模型?
从概率分布的角度来讲,生成式模型是对x与y的联合概率p(x,y)建模,而判别式模型是对x的条件下,y的条件概率p(y|x;θ)的建模。
- 判别式模型(结果导向): 根据原有数据集不同的类别数据,学习得到类别之间的差异。根据输入样本
x的特征判别其类别。所以它不关心数据是怎么生成的,而是只关心样本之间的差别,根据这种差异性进行分类。 - 生成式模型(源头导向): 尝试找出数据是怎么生成的,了解每一类样本的一种分布。要判别样本
x的类别,要与所有的y进行比较,实际预测结果取决于生成概率最大的y.一般而言生成式模型不做分类任务,因为它的分类效果远差于判别式模型。
生成式模型要学习数据分布,反映数据本身的相似度。
随着深度学习的出现以及神经网络的发展,利用神经网络模拟数据生成过程可以达到更好的效果,可以更好地在给定数据集的情况下,产生于数据集同分布的新样本。
- 训练数据集: 以图像为例(当然也可以是其他类型的数据,比如语音、文字、网络流量等等),每一张图像都可以看作是在一个分布 中抽样得到的样本,如果能够得到 我们就可以无限制地抽样出一些样本,也就可以得到一些与真实图像非常相近的生成图像(密度估计问题)。但可惜这个分布是不可知的(我们无法根据有限的数据集直接推导出一个高维分布)。
- 生成数据: 假设生成图像服从分布 ,使可控的已知的分布 与 尽可能接近,就可以近似得知 。
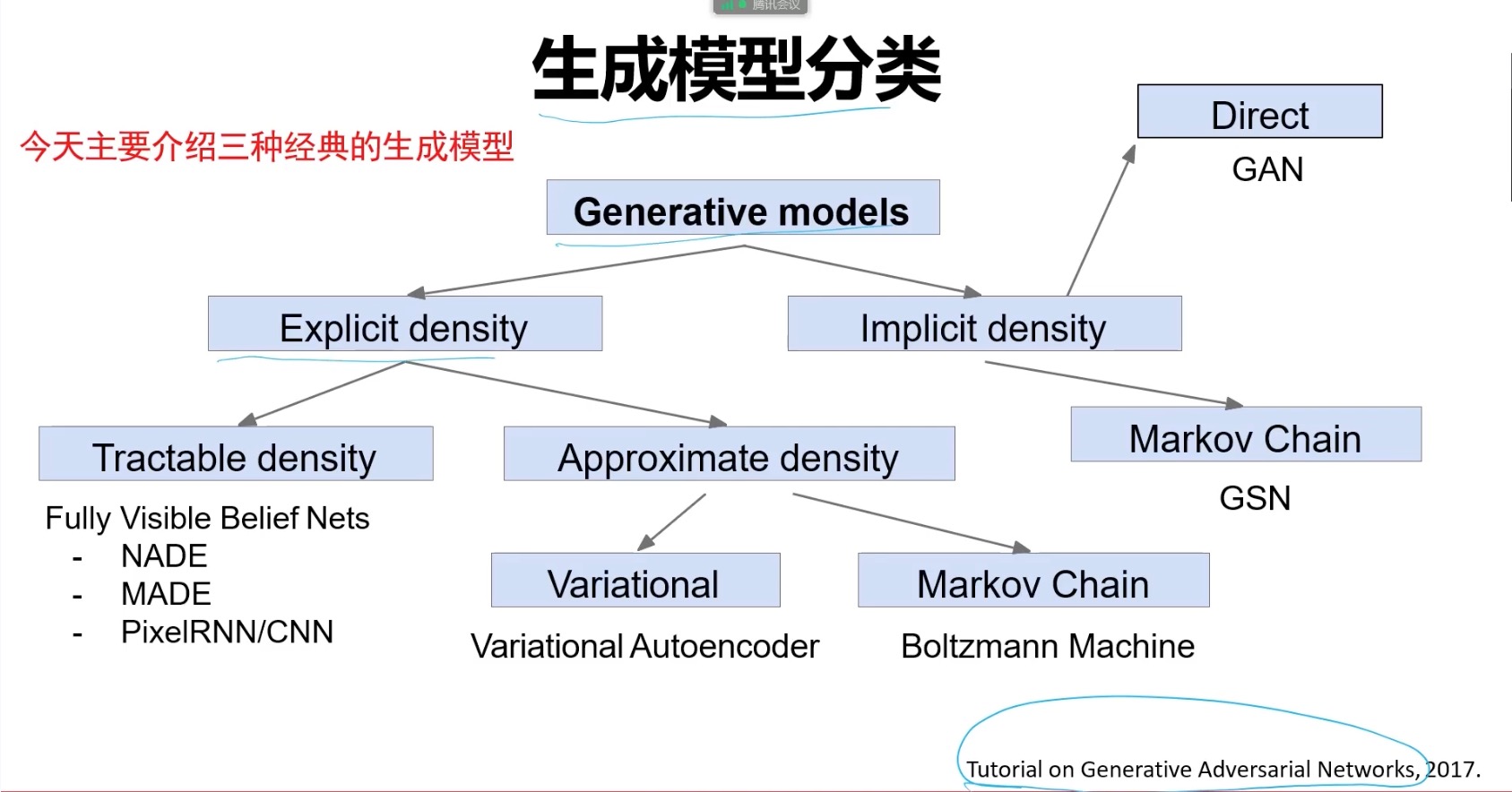
根据对 的定义是显式还是隐式的可以把生成式模型分为以下两类,比较有代表性的是VAE与GAN。
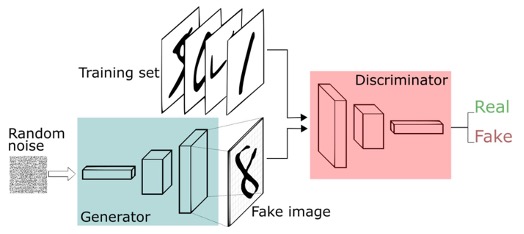
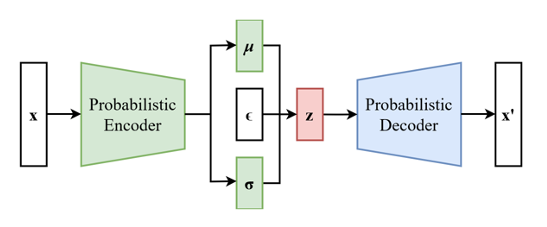
- 显式密度估计: 显式构建样本的密度估计函数 ,通过最大似然估计(优化模型参数来最大化在训练数据上的预测概率)来求解参数。
- 隐式密度估计: 不需要构建样本的密度估计函数,只需要拟合模型,使其能够生成复合数据分布的样本。
1.2 生成式模型有哪些应用?
在视觉领域,生成式模型主要应用于图像生成,图像生成可以分为有条件和无条件两种,有条件的图像生成通常指的是生成具体某一种类别的图像,而无条件图像生成只要生成与真实图像相似的一批图像就可以了。
在图像生成的基础上,有着许多形形色色的子领域(促进了一波艺(鬼)术(畜)的发展),有代表性的包括,图像编辑、风格迁移、文本图像生成、图像扩展、图像修复、根据深度图合成图像、根据语义图合成图像等等,在我看来,这些不同的任务也就是在原始的图像生成上增加了不同的先验信息,只是这些先验知识有的简单有的复杂,最简单的也就是标签,而复杂的就会有一些空间的信息,比如语义图,深度图什么的。而模型的输出同样都是一些图像(尽可能真实)。

碎碎念
那么我们为什么要研究生成式模型?我个人认为它是和创造力有关,当然这么想也不一定全面和准确。当前人工智能应该还在一个初级阶段,但它的出现,已然可以取代许多工作了,那些不需要创造力的,重复性的工作,一方面确实会造成失业问题,另一方面也确实在把人们从重复性的工作中解放出来,所以我认为它是利大于弊的。
而生成模型,它赋予了计算机模拟生成的能力,使它去创造一些原本世界上没有的东西,艺术、文学、诗歌,这些人类独有的元素。我曾看过一个节目,节目中主持人让所有人判断两首诗,哪一首是人写的,哪一首是机器写的,结果确实存在少数部分的人判断错了。前不久我看视频,发现有些生成器居然可以生成小说了,虽然一眼就能看出生成的文章十分粗糙低质,但它居然有了这种能力,一种合成有意义的语句的能力。对视频,对图像而言,这种例子更是数不胜数,合成人物演讲视频,合成一些人眼都看不出真假照片,这甚至都能对安全造成威胁。这说明,生成模型也确实发展到了一个新的高度,是好是坏不太好评判,但是很有趣,我只能这么说。要论威胁,我觉得还是要警惕一些的,科技是双刃剑的道理谁都懂。要论优势,它是否能解放劳动力?是否能让我们的生活更加便利?它研究的意义到底是什么?我没有想明白,我只知道它很好玩,而且可以数据增强哈哈哈哈。但是啊,如果“生成”这种任务完全完成了的话,那我们的很多资源是不是取之不尽,用之不竭了呢?
”如果我们制造出了和人智力相当的机器人,那么我们可以肯定的说生成模型一定是其中的一部分。“我在某篇博客上看到了这句话。如果要对生成模型溯源,它最基本的理论基础也不过是概率分布,要解决的是密度估计的问题。可本篇的介绍也不过是冰山一角罢了。
1.3 怎样评价生成样本的优劣?
一般而言,我们需要一个可量化的评价指标来衡量模型优劣,比如使用分类准确率评价分类模型的性能,使用均方误差评价回归模型的性能。对生成模型来讲也是如此。只是它的指标似乎没有那么直观。
生成样本的优劣一般指的是生成的图像的质量和多样性,其中质量衡量了生成的每一张图像是不是真实,这里的真实就包括了图像不能模糊,也不能清晰但是很奇怪,而多样性衡量了这一组生成的图像是不是足够分散,因为生成一组相似度很高的图像也是没什么意义的。以下是两类常用的指标。
1.3.1 Inception Score(IS)指标

IS指标是基于一批图像送入Inception模型分类的结果来计算的,它的最基本的思想是,对一张图像而言,分类结果越集中,说明这张图像质量越好(毕竟质量足够好计算机才能清晰地认识它),而对于一批图像而言,分类结果应该尽可能分散,也就是说这批图像应该尽可能平均地分布在每个类别中,这样做的原因是出于对多样性的考虑。
而分散、集中等用信息的角度考虑,是熵的一种体现(熵:信息量越大,熵越大,数据越随机),综合两个指标,IS采用互信息(给定一个随机变量后,另一个随机变量的不确定性减少程度,也叫信息增益)的概念,用以描述给定生成样本以后,原始标签不确定性的减少程度(就是样本质量比较好嘛),IS的表达式简要推导:
其中,KL散度衡量两个分布之间的距离。
- H(y):最大化,也就是对于输入的样本,通过inception_v3模型后的类别要均衡,衡量模式坍塌。
- H(y|x):最小化,说明对输入的样本,通过inception_v3模型后预测的某一类别的置信度要高,衡量图像生成的质量。
所以IS指标越大越好。
IS指标存在的问题:
- 偏爱ImageNet中的物体类别,泛化性差。
- 类内模式崩溃问题,某一类的图像集中到一个点。
1.3.2 Fréchet Inception Distance(FID)指标

FID指标比IS指标更看重真实数据的影响,它会取生成样本与真实样本的2048个中间特征进行比较,假设中间特征符合多元高斯分布,计算两个分布之间的弗雷歇距离,FID的数值越小,表示两个高斯分布越接近。
所以FID指标越小越好。
实践中发现,FID对噪声具有比较好的鲁棒性,能够对生成图像的质量有比较好的评价,其给出的分数与人类的视觉判断比较一致,并且FID的计算复杂度并不高。整体而言,FID还是比较有效的,其理论上的不足之处在于:高斯分布的简化假设在实际中并不成立。