Weekly-221015
本文最后更新于:October 16, 2022 pm
周记:论文阅读(不含工作日)
Foundation Transformers
Foundation Transformers
[1]随着Transformer的发展与完善,人工智能领域的许多任务都有了相关的应用(如Vision、Language与Speech等)。由于任务的不同,我们通常会采用不同的网络架构。
1. 引言
- 目的: 提出
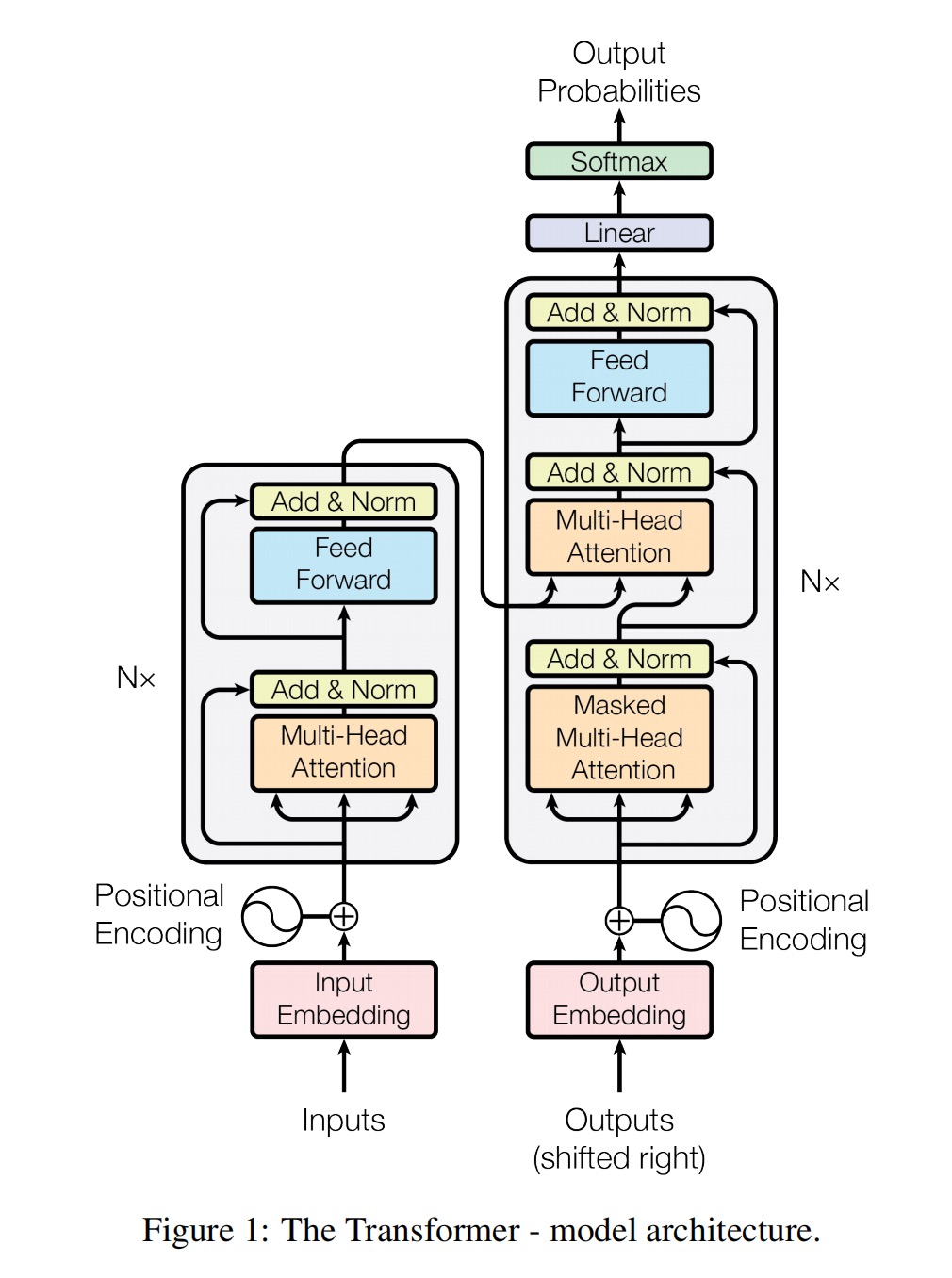
MAGNETO,建立Transformer的通用模型,介绍其不同的变种(针对不同任务),保证训练稳定性。 - 基础的Transformer模型: [2]如下图所示,以注意力机制连接编码器(左)与解码器(右),是一个实现seq2seq的模型,最初在机器翻译的任务上体现了其独特的优势(对长距离信息提取十分有效)。
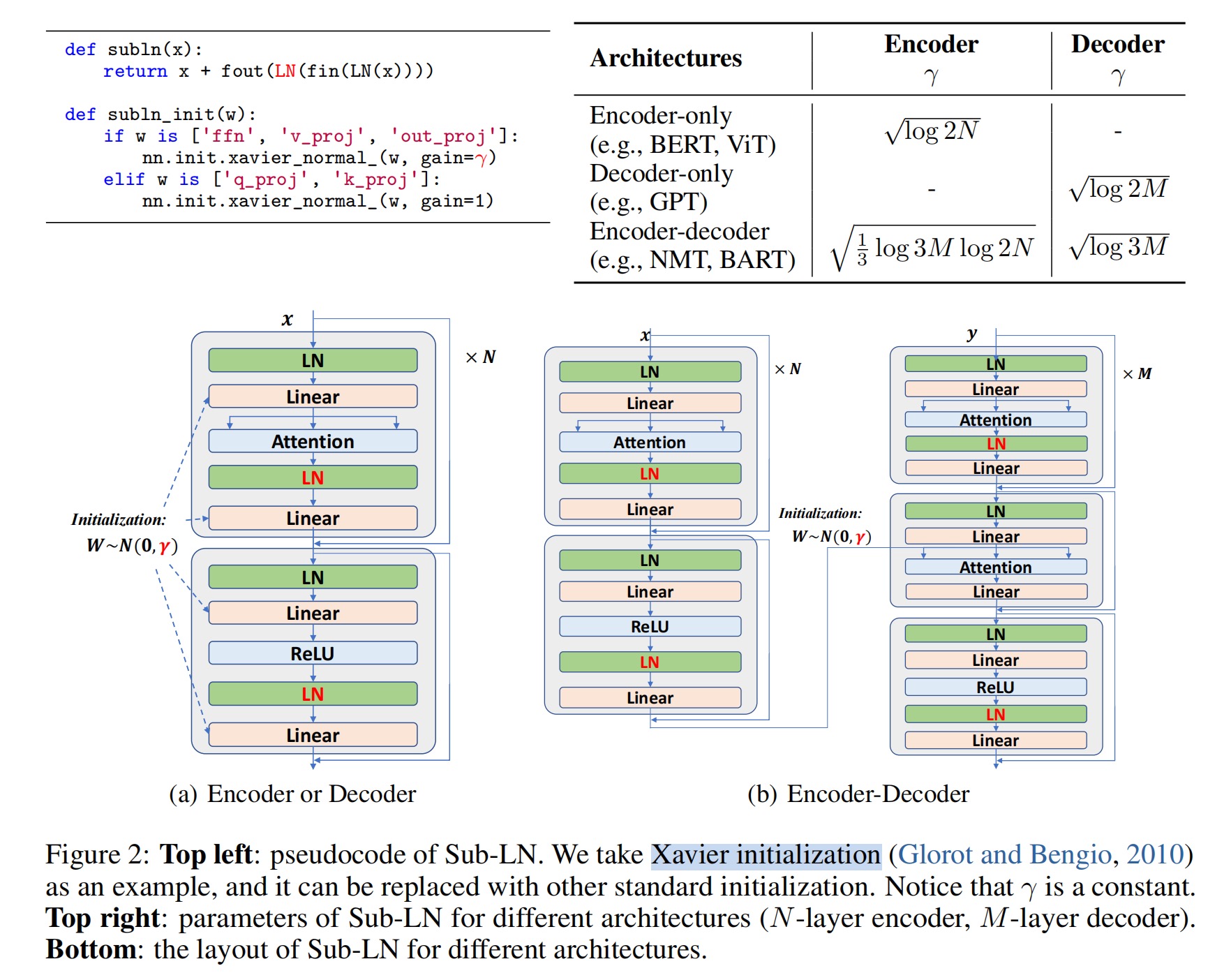
MAGNETO的改进:网络结构与初始化方法。- 网络结构: 与
Pre-LN相比,Sub-LN对每一个子层(multi-head self-attention、feed-forward network)的输入投影之前和输出投影之前引入了另一种层归一化机制。 - 初始化方法: 采用
DeepNet[3]的初始化机制,这一做法极大提高了训练稳定性,可无副作用地使模型尺寸放大(也就是层数变多)。
- 网络结构: 与
2. 网络结构:Sub-LayerNorm
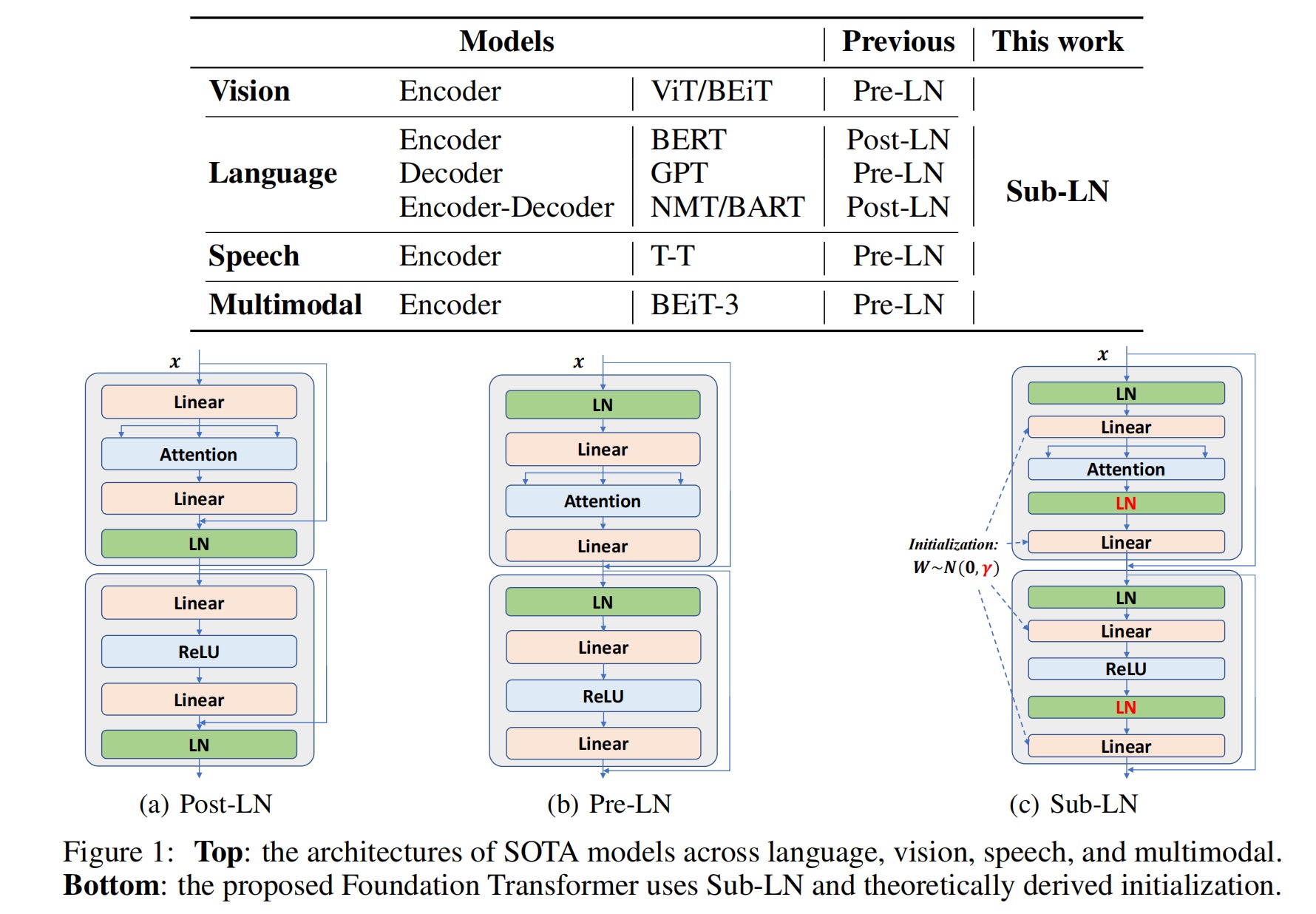
- 在输入的qkv投影之前加入的LN层: 其中,W代表多头注意力机制的一些参数。
- 在前馈网络中加入的LN层: 其中, 代表非线性激活层。
3. 初始化方法:详细推导见DeepNet
- 结论: MAGNETO的初始化方法相比于原始模型更具稳定性(可适用于更大的模型)。
Pre-LN的预期模型更新:
- 前向传播过程: 其中 与 分别代表 子层 (Self- Attention MSA)的输入和输出。
- 前向计算表示: 其中W代表模型参数,参数量越多,说明模型越大。
MAGNETO的预期模型更新:
- 前向计算表示: 与上式对比。
方法对比:
- Pre-LN 参数更新

- MAGNETO 参数更新

- 对权重的处理: 见论文主要贡献图中表格部分。
- Pre-LN 参数更新
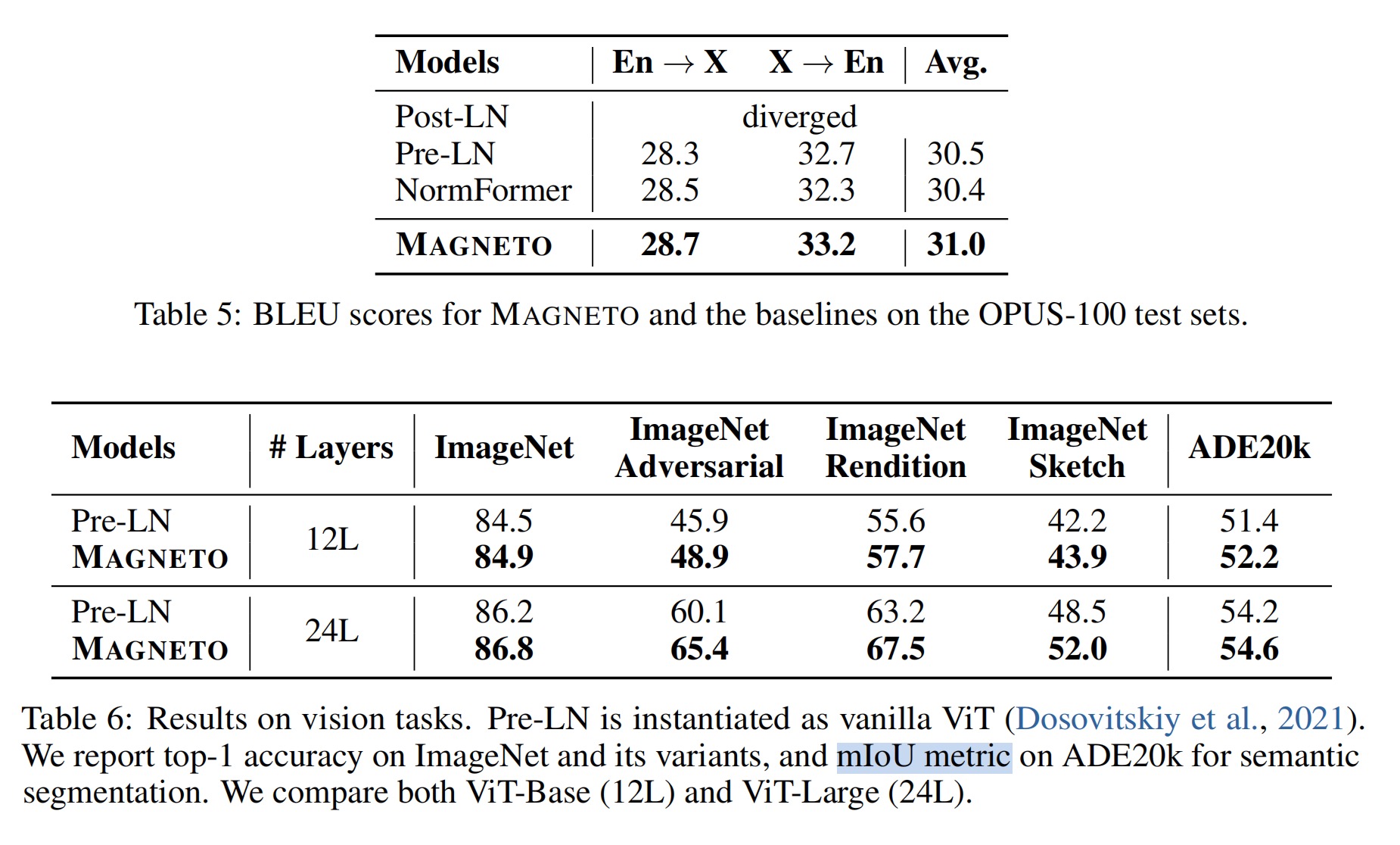
4. 实验部分:详见论文(贴一张视觉部分的)
5. 总结
- 本文主要目的是进一步提高Transformer的性能,其一是改变网络结构,增加LN层,其二是提高模型稳定性,对模型的参数进行一定的约束,得到一种更加通用的架构,并适用于尽可能多的模型规模。