Weekly-220612
本文最后更新于:June 12, 2022 am
本周学习汇报
电子信息实践课大作业扩散模型相关Hyperspherical Consistency RegularizationCoMatch- Semi-supervised Learning with Contrastive Graph RegularizationDiVAE : Photorealistic Images Synthesis with Denoising Diffusion Decoder
1. 电子信息实践课大作业

2. 关于扩散模型
2.1 生成式学习的三个需求
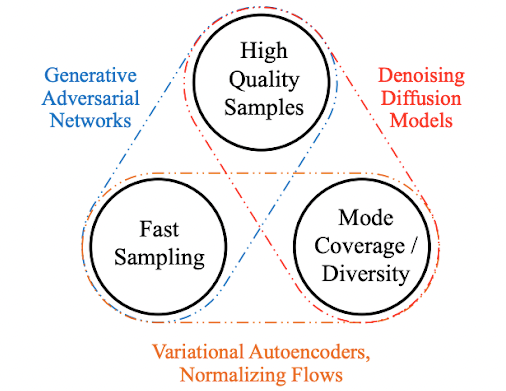
2.2 扩散模型的思想
正向扩散: 前向扩散过程通过逐渐扰动输入数据将数据映射为噪声。这是通过一个简单的随机过程正式实现的,该过程从数据样本开始,使用简单的高斯扩散核迭代生成噪声较大的样本。也就是说,在这个过程的每一步,高斯噪声都会逐渐添加到数据中。

参数化反向扩散: 参数化的反向过程,取消正向扩散并执行迭代去噪。这个过程代表数据合成,并经过训练,通过将随机噪声转换为真实数据来生成数据。它也被正式定义为一个随机过程,使用可训练的深度神经网络对输入图像进行迭代去噪。

2.3 扩散模型存在的问题-生成过程慢、采样慢
2.3.1 潜空间扩散模型
- NVIDIA 推出了
基于潜在分数的生成模型 ( LSGM ), 可以在潜在空间而不是直接在数据空间中训练扩散模型。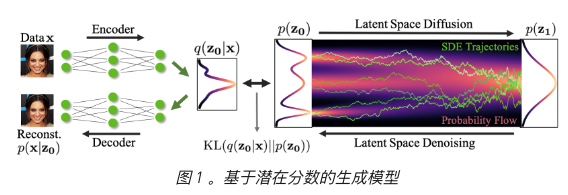
- 优势:合成速度、表现力,以及定制的编码器和解码器。
- 基本上简化了数据本身,首先将其嵌入平滑的潜在空间,在那里可以训练更有效的扩散模型。
2.3.2 临界阻尼朗之万扩散(CLD)
- 问题: 扩散模型中的一个关键因素是固定前向扩散过程,以逐渐扰动数据。与数据本身一起,它唯一地决定了去噪模型学习的难度。
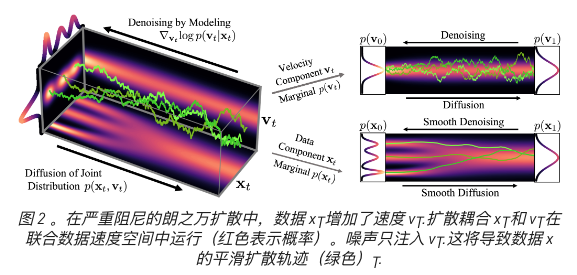
- 优势: 使用定制 SDE 解算器加速采样,有更简单的评价函数。
- 是一种改进的前向扩散过程,特别适合于更简单、更快的去噪和生成。
2.3.3 扩散算子去噪
- 使用条件 GAN 对去噪分布进行建模。

- 通过表达性多峰去噪分布,直接学习显著加速的反向去噪过程。
2.4 与VAE的对比

3. 关于对比学习中的正则化
题目: Hyperspherical Consistency Regularization

/2-Learn Method/4-Contrastive Learning/2022-Hyperspherical Consistency Regularization(CVPR).pdf
3.1. Introduction
- Common scheme of contrasive learning: Jointly training
supervised learningandunsupervised learningwith a shared feature encoder. Taking advantage of bothfeature-dependent informationfromself-supervised learningandlabel-dependent informationfromsupervised learning. - Motivation: This scheme remains suffering from bias of the classifier- the classifier which determines the ultimate predictions still suffers from the bias of semi-supervision or weak-supervision.
- Contributions:
- Analyze the relationship between the projection head and the classifier.
- Proposed: hyperspherical consistency regularization (HCR)- to regularize the classifier using feature-dependent information and thus avoid bias from labels.
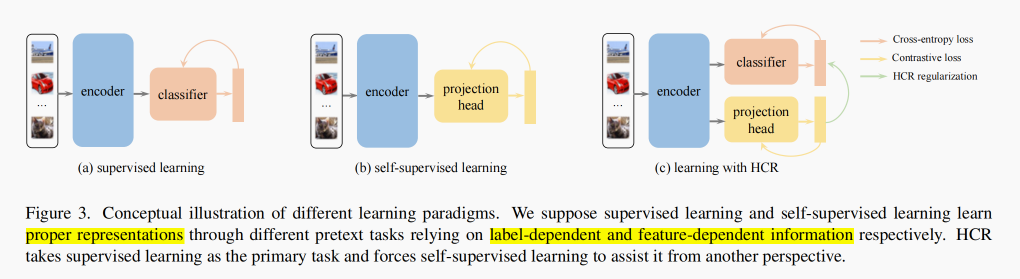
3.2. Related Work
- Contrastive learning: HCR builds a bridge between classical supervised learning and pretext tasks in self-supervised learning, and the regularization is plug-and-play to apply in these joint-learning methods.
- Learning on the hypersphere: Reprojects
the Euclidean feature spaceof the classifier intoa hypersphereand explores its connection with the projection head’s hypersphere.
3.3. Methodology

3.4. Experiments
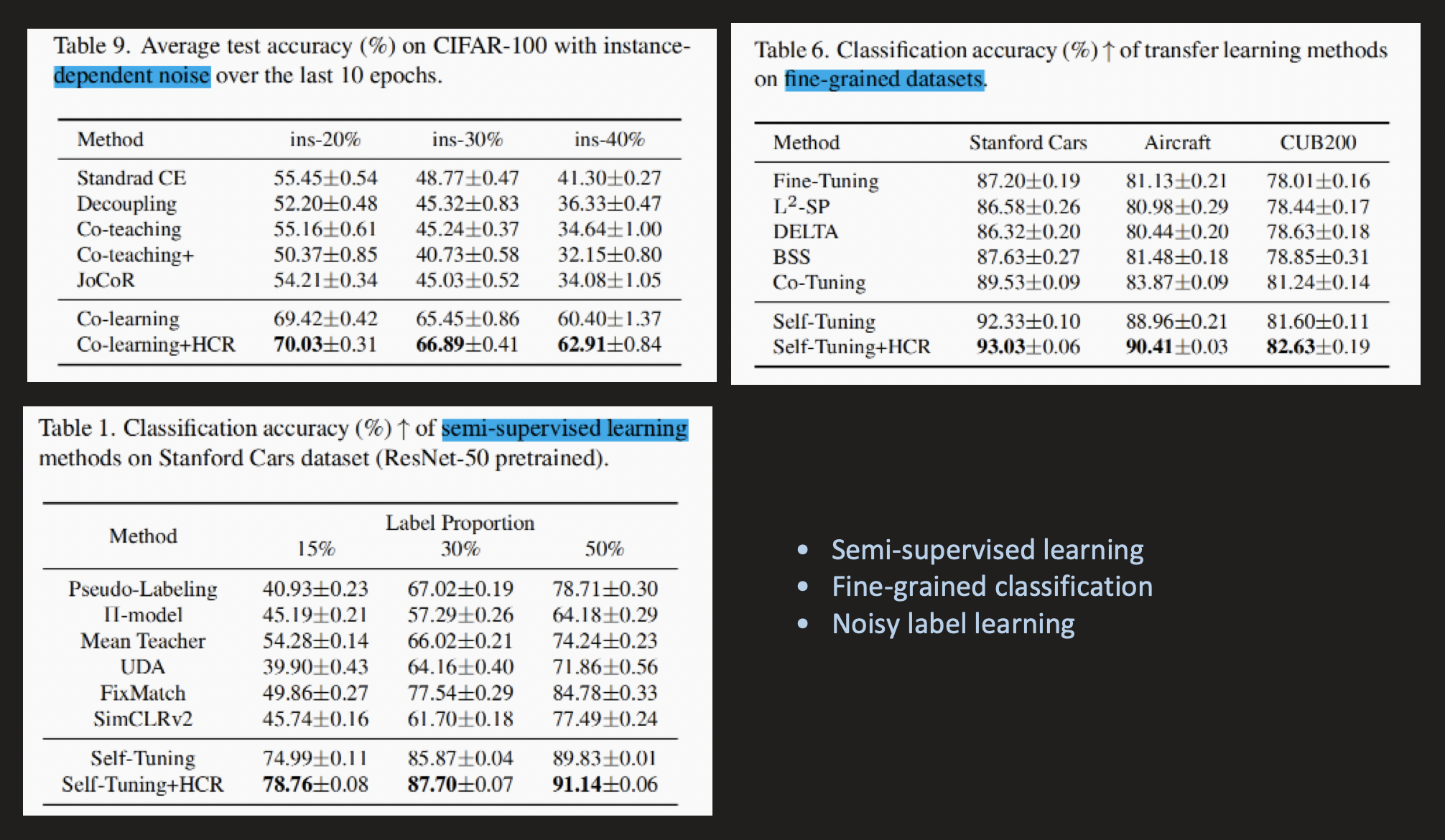
- Semi-supervised learning
- Fine-grained classification
- Noisy label learning
3.5. Conclusion and Future Work
- Propose a novel consistency regularization method for semi-supervised and weak-supervised learning, called hyperspherical consistency regularization (HCR).
- HCR: Encourage the pairwise distance distribution of the classifier to be similar to the distribution of the projection head in the latent space.
4. 半监督学习中的对比图正则化
CoMatch- Semi-supervised Learning with Contrastive Graph Regularization

GitHub/2-Learn Method/4-Contrastive Learning/2021-CoMatch- Semi-supervised Learning with Contrastive Graph Regularization(ICCV).pdf
4.1. Introduction
- Semi-supervised learning: learning from few labeled data and a large amount of unlabeled data.
- using the model’s class prediction to produce a pseudo-label for each unlabeled sample as the label to train against.BUT heavily rely on the quality of the model’s class prediction.
- unsupervised or self-supervised pre-training, followed by supervised fine-tuning and pseudo-labeling.BUT Self-supervised learning methods are task-agnostic.
- graph-based semi-supervised learning: Not shown competitive performance on ImageNet.
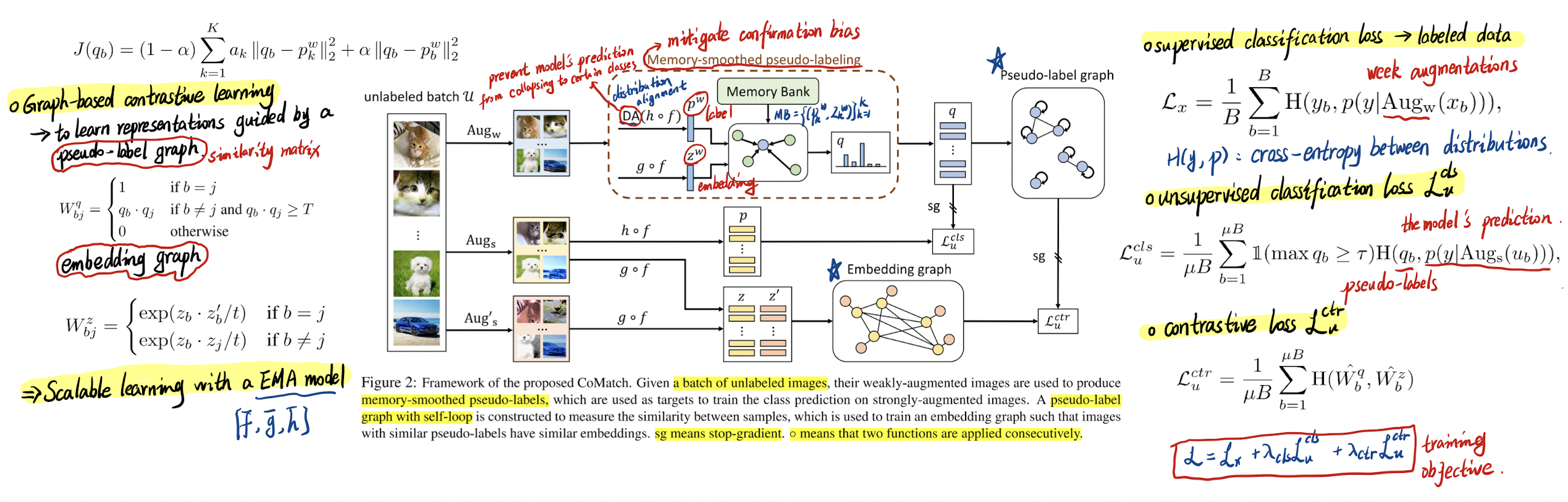
- CoMatch: a new semi-supervised learning method that addresses the existing limitations.
- The classification head: Using memory-smoothed pseudo-labels, where pseudo-labels are refined by aggregating information from nearby samples in the embedding space.
- The projection head: using contrastive learning on a pseudo-label graph, where samples with similar pseudo-labels are trained to have similar embeddings.

4.2. Related Work
- Consistency regularization.
- Entropy minimization.
- Self-supervised contrastive learning.
- Graph-based semi-supervised learning.
4.3. Methodology
- Overview
- CoMatch
- Memory-smoothed pseudo-labeling
- Graph-based contrastive learning
- Scalable learning with an EMA model
4.4. Experiments

4.5. Conclusion and Future Work
- Co-training of class probabilities and image embeddings.
- Memory-smoothed pseudo-labeling to mitigate confirmation bias.
- Graph-based contrastive learning to learn better representations.
5. 图像生成—去噪扩散解码器
DiVAE : Photorealistic Images Synthesis with Denoising Diffusion Decoder

/3-Generate/1-Network/5-DPM/2022-DiVAE - Photorealistic Images Synthesis with Denoising Diffusion Decoder.pdf
5.1. Introduction
- Diffusion models have shown be capacity to generate high-quality synthetic images.
- Propose: VQ-VAE architecture model with a diffusion decoder (DiVAE)—work as the reconstructing component in image synthesis.
- Motivation: generate more detailed and photorealistic images to improve the reconstructing stage of multi stage image synthesis.
- Compare:

5.2. Related Work
- Visual Synthesis: AR、GANs、VAEs、diffusion models and flow-based models.
- GANs: often difficult to train and defective in capturing of diversity.
- Auto-regressive (AR): generate model have advantages in density modeling and stable training.
- Diffusion models: likelihood-based models.
- Denoising diffusion probabilistic models (DDPM): Produce high-quality images and the promising prospect in visual synthesis.
- Denoising diffusion implicit models (DDIM): developed a approach to fast sampling.
- Guided Diffusion: find that samples from a class conditional diffusion model with a independent classifier guidance can be significantly improved.
- Classifier-Free Diffusion: propose classifier-free guidance that does not need to train a separate classifier model.
5.3. Methodology

5.4. Experiments
Quantitative Analysis:

Qualitative Analysis:

5.5. Conclusion and Future Work
- Proposes a DiVAE with
a diffusion decoderto generate more photorealistic and detailed images to improve the reconstructing stage of multi stage image synthesis. - Achieves state-of-the-art results on reconstruction of images comparing with existing approach and samples more detailed images on Text-to-Image tasks.
6. 下一步计划
- 扩散模型相关论文阅读
- 对比学习与视觉表征学习