Pytorch分布式数据并行运算和一个小工具
本文最后更新于:May 6, 2022 pm
Byobu的介绍:终端复用方法(类似tmux)
1. ssh链接中断解决方式
原因分析: 挂断信号(SIGHUP)默认的动作是终止程序。当终端接口检测到网络连接断开,将挂断信号发送给控制进程(会话期首进程)。如果会话期首进程终止,则该信号发送到该会话期前台进程组。一个进程退出导致一个孤儿进程组中产生时,如果任意一个孤儿进程组进程处于STOP状态,发送SIGHUP和SIGCONT信号到该进程组中所有进程。因此当网络断开或终端窗口关闭后,控制进程收到SIGHUP信号退出,会导致该会话期内其他进程退出。这里我认为我们的进程被杀掉也就是因为ssh与服务器之间的通信断掉了,这个通信断掉之后linux程序就默认将该连接下的所有进程都杀掉。
解决方式: 一个是使用nohup指令,一个是使用screen指令,最后一个是screen的升级版byobu。(我觉得byobu比较好)
2. Byobu是什么
维基百科: Byobu是与Linux计算机操作系统一起使用的GNU Screen 终端多路复用器或tmux的增强功能,可用于提供屏幕通知或状态,以及选项卡式多窗口管理。它旨在改善用户连接到远程服务器时的终端会话。
我的服务器上的效果:
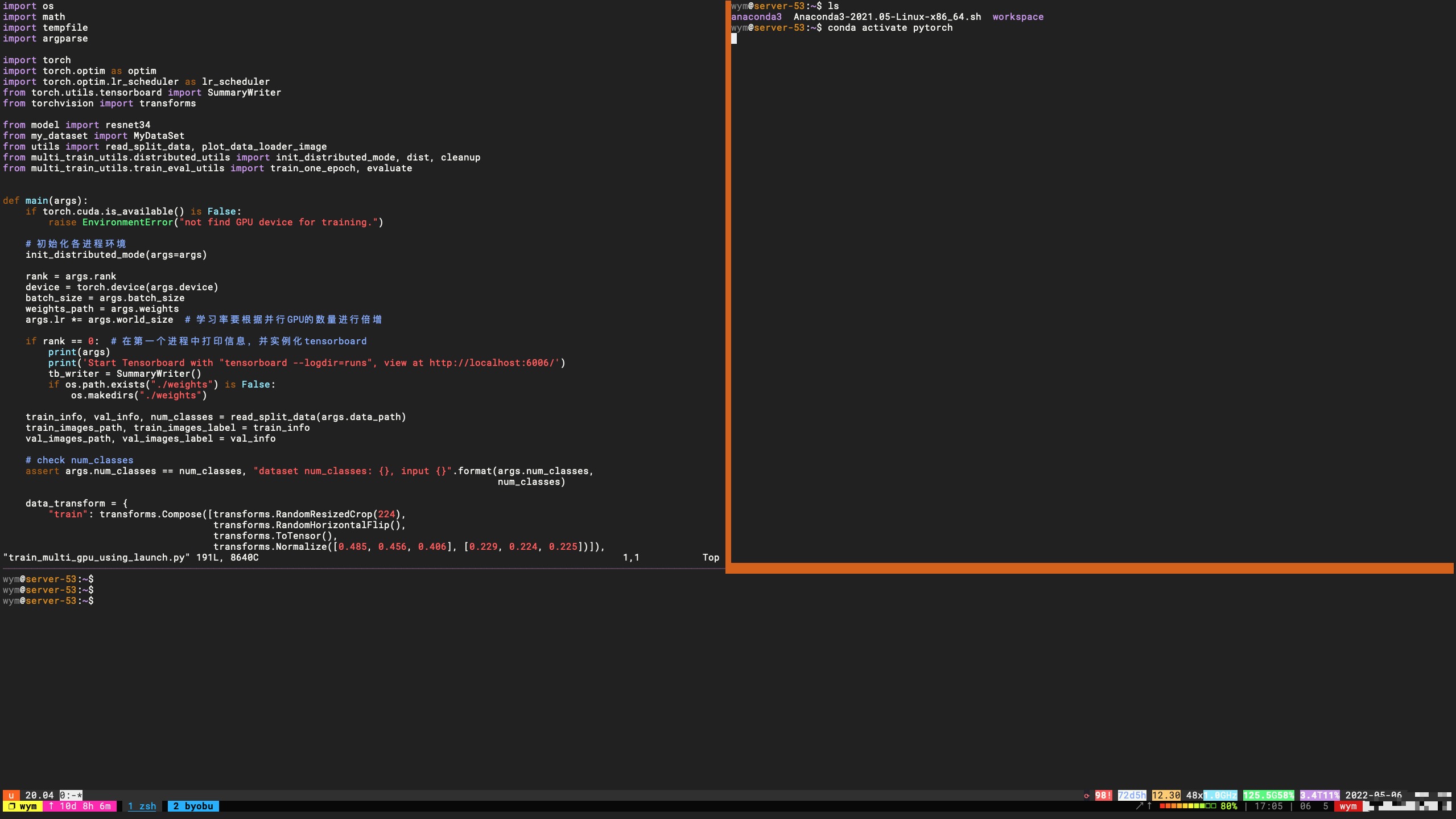
注:忽略最下面一行,那一行是我本地的tmux
3. Byobu的使用
3.1 加载与退出
加载
- 登录启动
byobu-enable表示Byobu窗口管理器将在每次文本登录时自动启动byobu-disable表示Byobu窗口管理器将不再在登录时自动启动 - 色彩提示
byobu-enable-prompt启动Byobu的彩色提示byobu-disable-prompt禁用Byobu的彩色提示
退出byobu detach
3.2 使用方法
指令形式
注:如果在tmux中再连接服务器使用Byobu,可能会有按键冲突,一是可以通过电脑的快捷键修改解决,而是别这么嵌套使用。我的tmux主要依赖Ctrl-b,Byobu依赖Ctrl-a,但是涉及Fn时就很迷。
Ctrl-a k - 关闭当前窗口(y/n)
Ctrl-a ↑ - 将焦点移动到上边分割区域 (如果上边存在分割区的话)
Ctrl-a ↓ - 将焦点移动到下边分割区域 (如果下边存在分割区的话)
Ctrl-a ← - 将焦点移动到左边分割区域 (如果左边存在分割区的话)
Ctrl-a → - 将焦点移动到右边分割区域 (如果右边存在分割区的话)
Ctrl-a 数字 - 移动到指定窗口
Ctrl-a $ - 显示详细状态 (不知道具体作用)
Ctrl-a R - 重新加载配置文件 (不知道具体作用)
Ctrl-a ! - 打开和关闭键绑定 (不知道具体作用)
Ctrl-a ~ - 保存当前窗口的回滚缓冲区 (不知道具体作用)
Ctrl+a | 垂直分割当前窗口
Ctrl+a % 水平分割当前窗口
Ctrl+a Ctrl+键盘方向键 设置分隔窗口大小
修改默认绑定的ctrl+a键,F9->change escape sequence->直接进行修改,比如改成ctrl+z. 举例,比如修改成ctrl+z后,分隔窗口之间的切换就是先ctrl+z然后在按方向键(不再是ctrl+a后再方向键了)
Byobu页低状态栏信息说明(版本不一样状态略有差别):
第一部分是ubuntu的标志logo,第二部分是ubuntu的版本,第三部分是byobu开启的窗口列表,当前列表会有一个”*”的标志,第四部分是开机时间和负载信息(uptime命令),第五部分是系统盘使用统计信息,最后面是日期时间.
p.s.:可自行修改底部状态栏:F9后tab键选择”Toggle status notifications(通知状态开关)”
快捷键形式(也可以直接Fn + Shift + 1在Byobu中查看或者 man byobu)
F2 - 创建一个新的窗口
F3 - 移动到下一个窗口
F4 - 移动到上一个窗口
F5 - 重新加载配置文件
F6 - 断开链接(可以通过 byobu -r 恢复)
F7 - 进入复制/回滚模式。这允许您将当前窗口中的文本及其历史记录复制到粘贴缓冲区中。在此模式下,一个类似于vi的全屏编辑器处于活动状态.
F8 - 重命名窗口
F9 - 菜单配置
F12 - 锁定当前命令行(不知道具体作用)
shift-F2 - 水平分割当前窗口
ctrl-F2 - 垂直分割当前窗口
shift-F3 - 将焦点移动到前一个分割区域
ctrl-F3 - 将当前分割区域与前一个分割区域替换
shift-F4 - 将焦点移动到下一个分割区域
ctrl-F4 - 将当前分割区域与下一个分割区域替换
shift-↑↓←→ 切换分割区
shift-F5 - 加入所有分割区域(没有尝试成功)
ctrl-F6 - 删除此拆分割区域
ctrl-F5 - 重新连接GPG和SSH套接字(不知道具体作用)
shift-F6 - 分离,但不会退出(可以通过 byobu -r 恢复)
ctrl-shift-F2 创建一个新的Session会话
alt-pgup - 进入回滚模式 往前寻找Session会话
alt-pgdn - 进入回滚模式 往后寻找Session会话
Pytorch分布式数据并行运算
1. 多GPU的使用
1.1 多GPU的两种情况
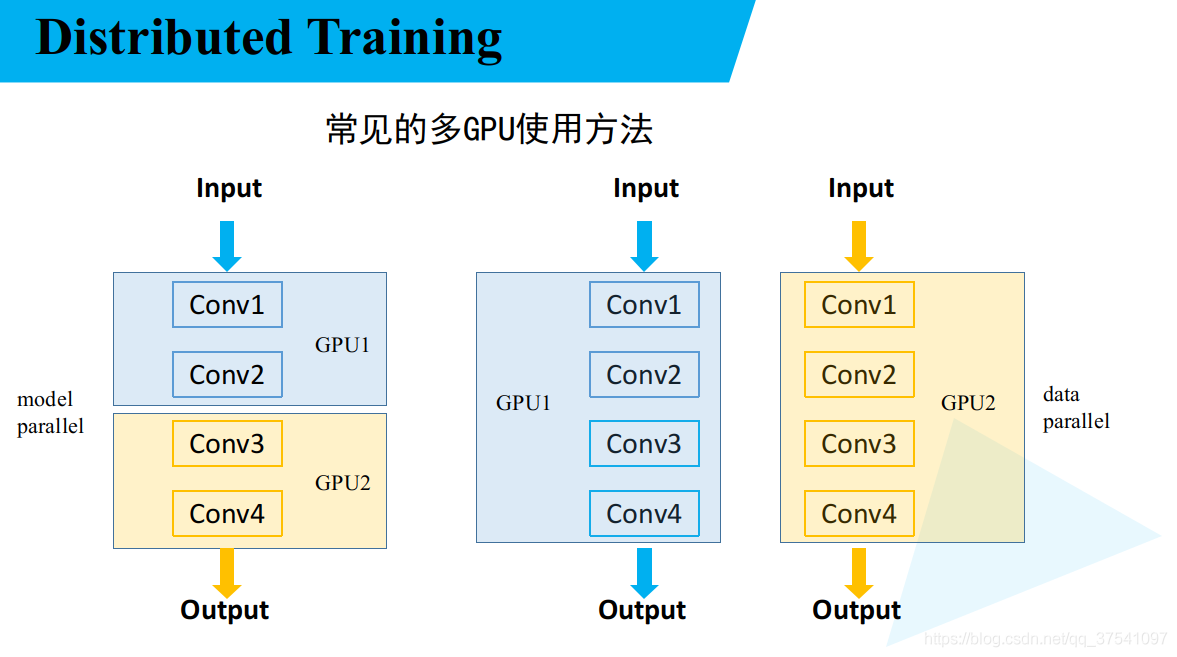
- 左边模型并行化,右边数据并行化。
1.2 多GPU数据处理需要考虑的问题
- 数据如何分配至各设备当中。
- 误差梯度如何在不同的设备之间进行通信。
- BatchNormalization如何在不同设备间同步。
2. python的os.environ模块
2.1 对Linux服务器而言
- os.environ[‘USER‘]:当前使用用户。
- os.environ[‘LC_COLLATE’]:路径扩展的结果排序时的字母顺序。
- os.environ[‘SHELL’]:使用shell的类型。
- os.environ[‘LAN’]:使用的语言。
- os.environ[‘SSH_AUTH_SOCK‘]:ssh的执行路径。
2.2 对分布式训练而言
- RANK:通常假定rank 0是第一个进程或者主进程,其他每个进程都有对应的进程号。
- LOCAL_RANK:进程内部的GPU的编号,非显式参数,由
torch.distributed.launch内部指定。一个进程可以对应多块GPU,编号从0开始。 - WORLD_SIZE:全局的进程个数。
- SLURM_PROCID:可以用作全局的RANK。
3. 关于 nn.DataParallel 和 DistributedDataParallel 的区别
3.1 问题描述
- 问题:
UserWarning: nn.ParameterDict is being used with DataParallel but this is not supported. This dict will appear empty for the models replicated on each GPU except the original one. - 解释: 在现行版本的PyTorch中如果你的模型包含ParameterList(或者ParameterDict),那么使用DataParallel进行多卡训练会导致这个Parameter{List/Dict}没法成功复制到其他卡上。来源
3.2 DataParallel的并行化机制

- GPU0作为master进行梯度的汇总和模型的更新,再将计算任务下发给其他GPU,所以它内存和使用率会比其他的高。
3.3 DistributedDataParallel的并行化机制
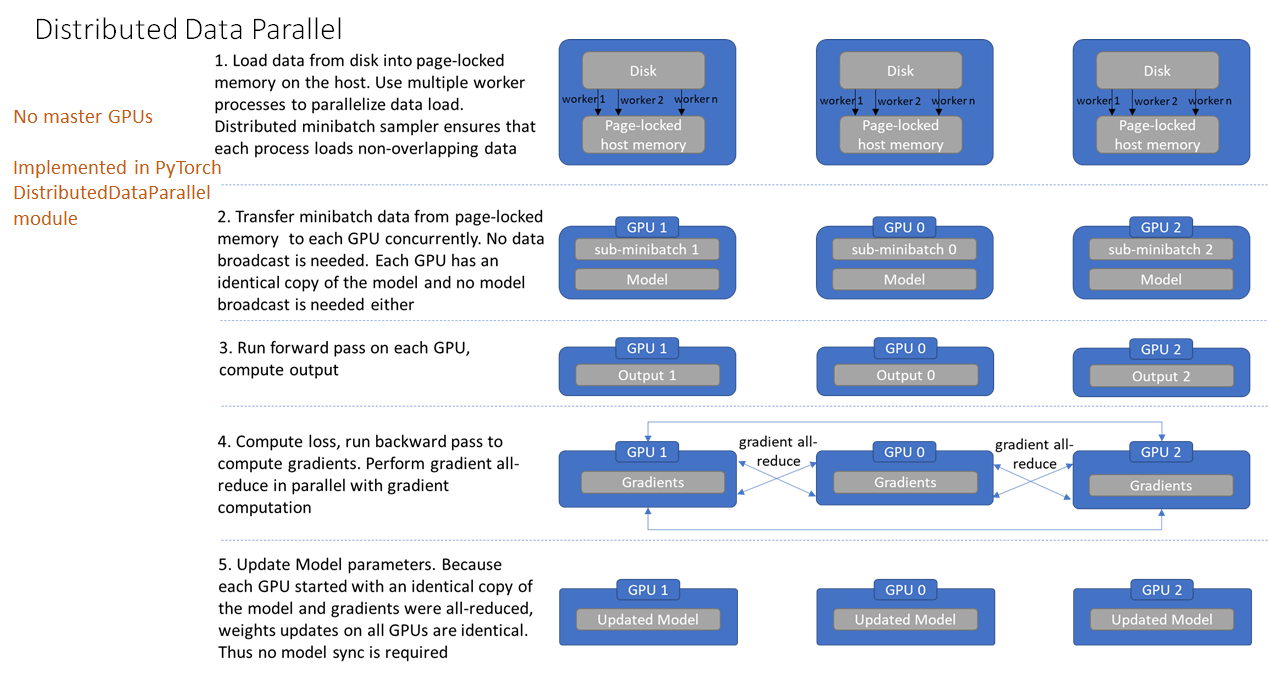
- torch自动将其分配给n个进程,分别在n个GPU上运行。不再有主GPU,每个GPU执行相同的任务。
3.4 并行化方式的区别
- DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而
DataParallel()是通过单进程控制多线程来实现的。还有一点,DDP也不存在前面DP提到的负载不均衡问题。 - 参数更新的方式不同。DDP在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由
rank=0的进程,将其broadcast到所有进程后,各进程用该梯度来独立的更新参数而 DP是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余的GPU。由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个optimizer,对各个GPU上梯度进行求平均,而在主卡进行参数更新,之后再将模型参数broadcast到其他GPU.相较于DP, DDP传输的数据量更少,因此速度更快,效率更高。 - DDP支持
all-reduce(指汇总不同 GPU 计算所得的梯度,并同步计算结果),broadcast,send和receive等等。通过MPI实现CPU通信,通过NCCL实现GPU通信,缓解了进程间通信有大的开销问题。
3.5 结论
- 推荐使用
DistributedDataParallel。 - 需要
python -m torch.distributed.launch --nproc_per_node=8 --use_env main.py为每个节点启动多个进程以进行分布式训练,它在每个训练节点上产生多个分布式训练进程。