Weekly-211024
本文最后更新于:October 24, 2021 pm
本周学习汇报
《Alias-Free Generative Adversarial Networks》[1]Code of StyleGAN3[2]
1. StyleGAN3(NeurIPS 2021)

1.1 Motivation
如上图所示,StyleGAN2在图像生成中,图像细节特征的平移与旋转效果很差,即纹理特征会很大程度地依赖于坐标。StyleGAN3的提出,为解决StyleGAN2图像坐标与特征粘连的问题,主要修改生成器的设计,得到一个更自然的转换层次结构,使纹理与坐标一起移动。视觉效果上,可以使生成物体在空间中更连贯地移动,使GAN更适合视频与动画的生成。
- Alias:描述样本重建过程中,与原始样本不同的失真或伪影(如摩尔纹)。
1.2 Method
1.2.1 BaseLine——StyleGAN2
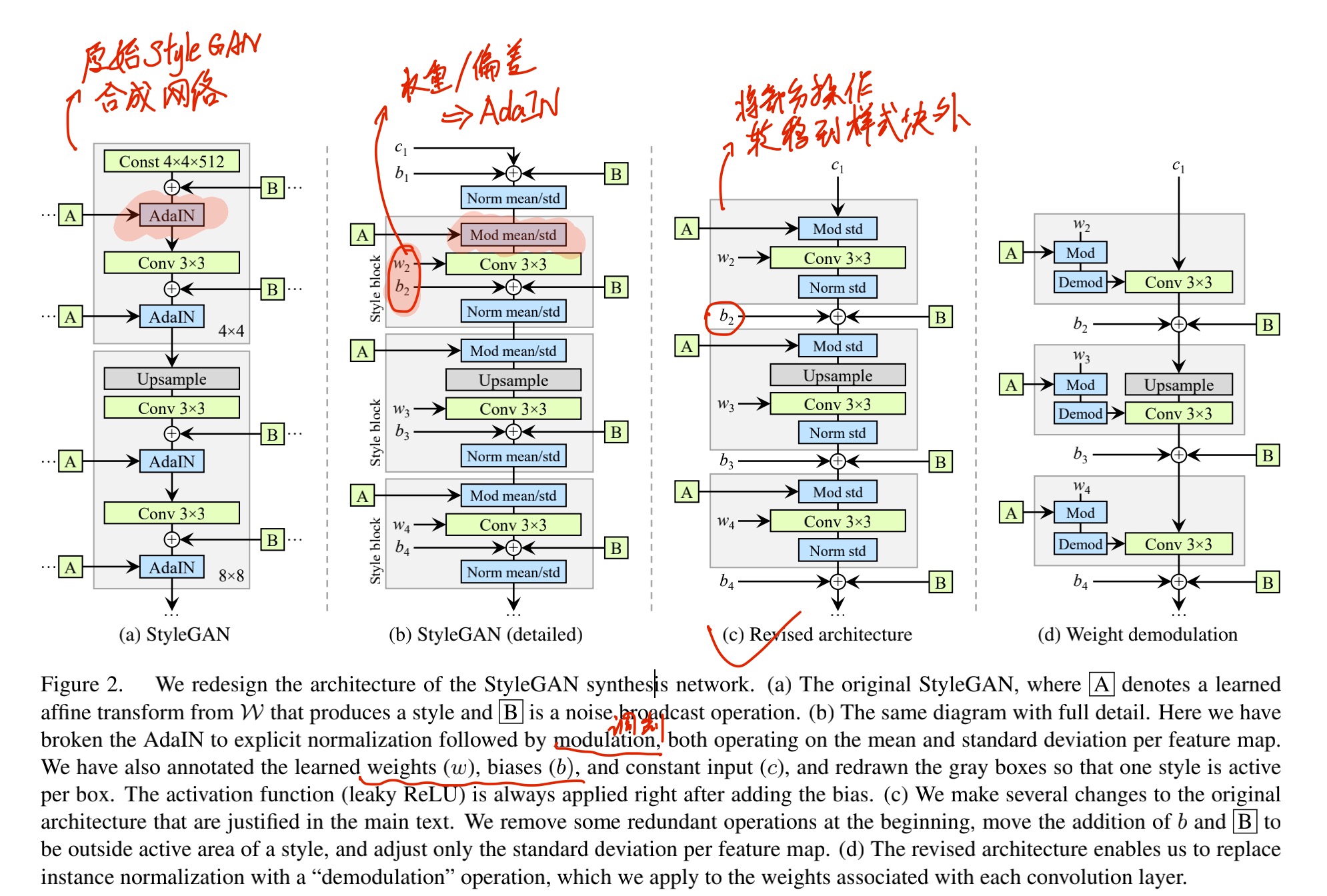
1.2.2 Fourier features
为了从输入的潜代码中更好地提取平移与旋转的连续特征,将生成器的学习常数输入替换为与原始 4x4 分辨率匹配的固定傅立叶特征(圆形频带内的均匀采样频率 = 2),这一改变略微提高了FID的指标,更重要的贡献在于不必估算操作t,而可以直接计算图像不变性的指标。
1.2.3 No noise inputs
由于逐像素噪声输入独立于底层特征的任意变换,因此去除这些输入,并从下层粗糙特征中继承亚像素的位置信息。
1.2.4 Simplified generator
映射网络深度减少,禁用混合正则化和路径长度正则化。在每次卷积之前,与输出的跳过连接被特征图的归一化所取代。所有这些变化都使 FID 保持不变,并略微提高了不变性的测量指标。
1.2.5 Boundaries & upsampling
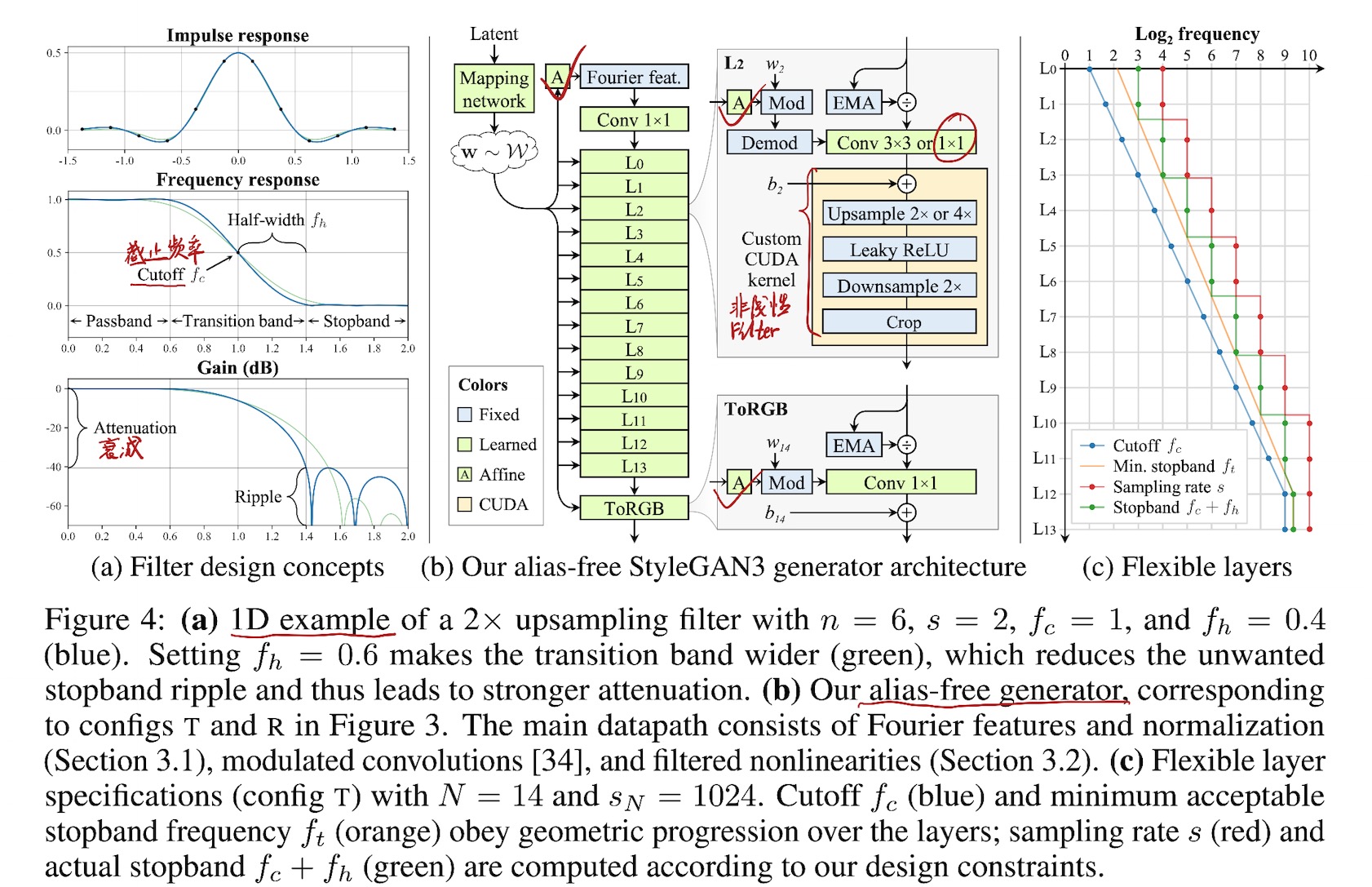
图像边界填充过程中,会导致图像绝对坐标泄漏到内部表示中(不利于平移旋转的不变性),因此留出10像素的间隔。在理论模型的引导下,采用临界采样的方式,用Kaiser窗口n=6(每个输入像素影响6个输出像素,每个输出像素受6个输入像素影响)的sinc滤波器替换原有的双线性上采样滤波器。
1.2.6 Filtered nonlinearities
在连续域中应用ReLU激活函数,会导致非常高的频率无法在特征中表达,因此将“上采样->LReLU->下采样”的方式应用在网络结构中,以近似解决此问题。
1.2.7 Non-critical sampling
除高分辨率层外,其他层使用较低的截止频率,截止频率与feature map的数量成反比,以补偿信号中减少的空间信息。
1.2.8 Transformed Fourier features
在傅立叶特征之前添加了额外的仿射变换,允许生成器基于样式向量具有明确的旋转和平移参数。
1.2.9 Flexible layers (StyleGAN3-T)
在14层的生成器中,采用不同的截止频率,以最大程度地抑制Alias。
1.2.10 Rotation equiv. (StyleGAN3-R)
为实现旋转不变性,文章采用了两种措施,其一是用1x1卷积代替3x3卷积,此时只有上下采样分散像素间的信息;其二是采用一个径向对称jinc滤波器代替基于sinc的下采样滤波器。
1.3 Result

2. StyleGAN3实现
- 生成器结构[2]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class Generator(torch.nn.Module):
def __init__(self,
z_dim, # Input latent (Z) dimensionality.
c_dim, # Conditioning label (C) dimensionality.
w_dim, # Intermediate latent (W) dimensionality.
img_resolution, # Output resolution.
img_channels, # Number of output color channels.
mapping_kwargs = {}, # Arguments for MappingNetwork.
**synthesis_kwargs, # Arguments for SynthesisNetwork.
):
super().__init__()
self.z_dim = z_dim
self.c_dim = c_dim
self.w_dim = w_dim
self.img_resolution = img_resolution
self.img_channels = img_channels
self.synthesis = SynthesisNetwork(w_dim=w_dim, img_resolution=img_resolution, img_channels=img_channels, **synthesis_kwargs)
self.num_ws = self.synthesis.num_ws
self.mapping = MappingNetwork(z_dim=z_dim, c_dim=c_dim, w_dim=w_dim, num_ws=self.num_ws, **mapping_kwargs)
def forward(self, z, c, truncation_psi=1, truncation_cutoff=None, update_emas=False, **synthesis_kwargs):
ws = self.mapping(z, c, truncation_psi=truncation_psi, truncation_cutoff=truncation_cutoff, update_emas=update_emas)
img = self.synthesis(ws, update_emas=update_emas, **synthesis_kwargs)
return img - 映射网络[2]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56class MappingNetwork(torch.nn.Module):
def __init__(self,
z_dim, # Input latent (Z) dimensionality.
c_dim, # Conditioning label (C) dimensionality, 0 = no labels.
w_dim, # Intermediate latent (W) dimensionality.
num_ws, # Number of intermediate latents to output.
num_layers = 2, # Number of mapping layers.
lr_multiplier = 0.01, # Learning rate multiplier for the mapping layers.
w_avg_beta = 0.998, # Decay for tracking the moving average of W during training.
):
super().__init__()
self.z_dim = z_dim
self.c_dim = c_dim
self.w_dim = w_dim
self.num_ws = num_ws
self.num_layers = num_layers
self.w_avg_beta = w_avg_beta
# Construct layers.
self.embed = FullyConnectedLayer(self.c_dim, self.w_dim) if self.c_dim > 0 else None
features = [self.z_dim + (self.w_dim if self.c_dim > 0 else 0)] + [self.w_dim] * self.num_layers
for idx, in_features, out_features in zip(range(num_layers), features[:-1], features[1:]):
layer = FullyConnectedLayer(in_features, out_features, activation='lrelu', lr_multiplier=lr_multiplier)
setattr(self, f'fc{idx}', layer)
self.register_buffer('w_avg', torch.zeros([w_dim]))
def forward(self, z, c, truncation_psi=1, truncation_cutoff=None, update_emas=False):
misc.assert_shape(z, [None, self.z_dim])
if truncation_cutoff is None:
truncation_cutoff = self.num_ws
# Embed, normalize, and concatenate inputs.
x = z.to(torch.float32)
x = x * (x.square().mean(1, keepdim=True) + 1e-8).rsqrt()
if self.c_dim > 0:
misc.assert_shape(c, [None, self.c_dim])
y = self.embed(c.to(torch.float32))
y = y * (y.square().mean(1, keepdim=True) + 1e-8).rsqrt()
x = torch.cat([x, y], dim=1) if x is not None else y
# Execute layers.
for idx in range(self.num_layers):
x = getattr(self, f'fc{idx}')(x)
# Update moving average of W.
if update_emas:
self.w_avg.copy_(x.detach().mean(dim=0).lerp(self.w_avg, self.w_avg_beta))
# Broadcast and apply truncation.
x = x.unsqueeze(1).repeat([1, self.num_ws, 1])
if truncation_psi != 1:
x[:, :truncation_cutoff] = self.w_avg.lerp(x[:, :truncation_cutoff], truncation_psi)
return x
def extra_repr(self):
return f'z_dim={self.z_dim:d}, c_dim={self.c_dim:d}, w_dim={self.w_dim:d}, num_ws={self.num_ws:d}' - 分析网络[2]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88class SynthesisNetwork(torch.nn.Module):
def __init__(self,
w_dim, # Intermediate latent (W) dimensionality.
img_resolution, # Output image resolution.
img_channels, # Number of color channels.
channel_base = 32768, # Overall multiplier for the number of channels.
channel_max = 512, # Maximum number of channels in any layer.
num_layers = 14, # Total number of layers, excluding Fourier features and ToRGB.
num_critical = 2, # Number of critically sampled layers at the end.
first_cutoff = 2, # Cutoff frequency of the first layer (f_{c,0}).
first_stopband = 2**2.1, # Minimum stopband of the first layer (f_{t,0}).
last_stopband_rel = 2**0.3, # Minimum stopband of the last layer, expressed relative to the cutoff.
margin_size = 10, # Number of additional pixels outside the image.
output_scale = 0.25, # Scale factor for the output image.
num_fp16_res = 4, # Use FP16 for the N highest resolutions.
**layer_kwargs, # Arguments for SynthesisLayer.
):
super().__init__()
self.w_dim = w_dim
self.num_ws = num_layers + 2
self.img_resolution = img_resolution
self.img_channels = img_channels
self.num_layers = num_layers
self.num_critical = num_critical
self.margin_size = margin_size
self.output_scale = output_scale
self.num_fp16_res = num_fp16_res
# Geometric progression of layer cutoffs and min. stopbands.
last_cutoff = self.img_resolution / 2 # f_{c,N}
last_stopband = last_cutoff * last_stopband_rel # f_{t,N}
exponents = np.minimum(np.arange(self.num_layers + 1) / (self.num_layers - self.num_critical), 1)
cutoffs = first_cutoff * (last_cutoff / first_cutoff) ** exponents # f_c[i]
stopbands = first_stopband * (last_stopband / first_stopband) ** exponents # f_t[i]
# Compute remaining layer parameters.
sampling_rates = np.exp2(np.ceil(np.log2(np.minimum(stopbands * 2, self.img_resolution)))) # s[i]
half_widths = np.maximum(stopbands, sampling_rates / 2) - cutoffs # f_h[i]
sizes = sampling_rates + self.margin_size * 2
sizes[-2:] = self.img_resolution
channels = np.rint(np.minimum((channel_base / 2) / cutoffs, channel_max))
channels[-1] = self.img_channels
# Construct layers.
self.input = SynthesisInput(
w_dim=self.w_dim, channels=int(channels[0]), size=int(sizes[0]),
sampling_rate=sampling_rates[0], bandwidth=cutoffs[0])
self.layer_names = []
for idx in range(self.num_layers + 1):
prev = max(idx - 1, 0)
is_torgb = (idx == self.num_layers)
is_critically_sampled = (idx >= self.num_layers - self.num_critical)
use_fp16 = (sampling_rates[idx] * (2 ** self.num_fp16_res) > self.img_resolution)
layer = SynthesisLayer(
w_dim=self.w_dim, is_torgb=is_torgb, is_critically_sampled=is_critically_sampled, use_fp16=use_fp16,
in_channels=int(channels[prev]), out_channels= int(channels[idx]),
in_size=int(sizes[prev]), out_size=int(sizes[idx]),
in_sampling_rate=int(sampling_rates[prev]), out_sampling_rate=int(sampling_rates[idx]),
in_cutoff=cutoffs[prev], out_cutoff=cutoffs[idx],
in_half_width=half_widths[prev], out_half_width=half_widths[idx],
**layer_kwargs)
name = f'L{idx}_{layer.out_size[0]}_{layer.out_channels}'
setattr(self, name, layer)
self.layer_names.append(name)
def forward(self, ws, **layer_kwargs):
misc.assert_shape(ws, [None, self.num_ws, self.w_dim])
ws = ws.to(torch.float32).unbind(dim=1)
# Execute layers.
x = self.input(ws[0])
for name, w in zip(self.layer_names, ws[1:]):
x = getattr(self, name)(x, w, **layer_kwargs)
if self.output_scale != 1:
x = x * self.output_scale
# Ensure correct shape and dtype.
misc.assert_shape(x, [None, self.img_channels, self.img_resolution, self.img_resolution])
x = x.to(torch.float32)
return x
def extra_repr(self):
return '\n'.join([
f'w_dim={self.w_dim:d}, num_ws={self.num_ws:d},',
f'img_resolution={self.img_resolution:d}, img_channels={self.img_channels:d},',
f'num_layers={self.num_layers:d}, num_critical={self.num_critical:d},',
f'margin_size={self.margin_size:d}, num_fp16_res={self.num_fp16_res:d}']) - 指标:FID、perceptual_path_length、Inception score等
3. 其他
- 工程数学:Jordan标准型、欧氏空间、酉空间;
- 网络安全:Feistel密码;
- 高级算法分析:分支限界法;
- 高级机器学习:集成学习;
- 高级人机交互技术: Touch&Fold: A Foldable Haptic Actuator for Rendering Touch in
Mixed Reality
4. 下周计划
- 阅读之前看过的一些论文的代码并整理其逻辑结构;
- 继续学习相关论文。